
What is Technical SEO?
Technical SEO ensures that your website meets the technical requirements which modern search engines demand it. It comprises of following elements:
Essential elements of Technical SEO include
Crawling
Indexing
Rendering
Website architecture.
Why is Technical SEO Important?
Technical SEO helps you achieve the goal of better organic rankings. You have invested in overall SEO like great website design with the best content. But, your technical SEO is not in place. Sadly, you’re not going to rank.
What Does It Take to Rank?
Search engines such as Google and others must be able to find, crawl, render and index the pages on your website.
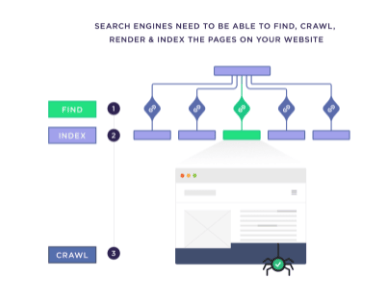
But this is just the tip of the iceberg. Even after Google indexes all of your site’s content, there is further work to do.
Things You Will Need To Do
To optimize your site for technical search engine parameters, the pages on your website must be secure, mobile-optimized, free of duplicate content, and fast-loading. Numerous factors go into a site’s technical optimization.
Though technical SEO is not a direct ranking factor per Google’s guidelines, it makes it easier for Google to access your content. This directly translates into giving you better chances for ranking.
How Can You Improve Your Technical SEO?
What comes to your mind when we say technical SEO-? Spiders, crawling, and indexing-isn’t it? But, the technical SEO is much wider. The parameters are vivid and have a wider scope.
Here are the critical factors you need to take into account for a Technical SEO Audit:
1. Page Canonicalization Issue
Canonical issues generally occur if a website has more than one URL with similar or identical content. It may be the consequence of the absence of proper redirects. However, canonical issues are also associated with search parameters present on e-commerce sites. They may occur due to syndicating or publishing content on several sites.
For example, a website might load its homepage for all of the following URLs:
 Here, you can get a picture of what happens. These are URLs of business and their respective websites. They have published the same page on their homepage urls. The home page of each of these sites has precisely the same content. But each website has a different URL. So, search engines understand it to be four other pages. This leads to a duplicate content problem, which will be an issue for SEO.
Here, you can get a picture of what happens. These are URLs of business and their respective websites. They have published the same page on their homepage urls. The home page of each of these sites has precisely the same content. But each website has a different URL. So, search engines understand it to be four other pages. This leads to a duplicate content problem, which will be an issue for SEO.
What Are Some Common Causes of Canonical Issues?
Various scenarios lead to canonical issues, but Google lists the following as the commonest ones.
HTTPS vs. HTTP: When an SSL certificate secures your site, it may load both the secured and the non-secured versions of the website. It will result in creating duplicates of all the single pages of your website.

Google considers these as different URLs with the same content. Hence, duplicacy arises again.
URLs Generation Settings for Different Devices Used to View the Page: having disparate websites for desktop users [site].com, mobile users, AMP sites vs.] amp.[site].com, it can lead to canonical issues.
Though there are many ways to create canonical issues on your site, the good thing is you can track the issues and fix them.
2. Improper Canonical Tags
Does Your Site Have Canonical Issues?
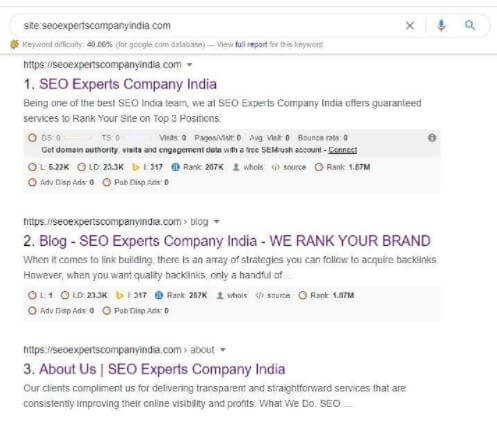
As mentioned already, canonical issues may result from HTTP/HTTPS or WWW/non-WWW and others. To find if these issues are present on your site, type all the possible versions of your site’s URL into your browser. For instance:
If these URLs redirect to one particular URL in the set (for example, each of those SEO Experts Company India URLs redirects to https://www.seoexpertscompanyindia.com), It means your site does not have the canonical issues. However, if any URLs do not redirect to the preferred URL, the site has a canonical issue.
This sounds simple. Isn’t it? However, there can be other challenging and time-consuming issues present. But a relatively straightforward way to discover things that could surprise you. Google, typing in site:[yoursite.com]
Review all of the pages in Google’s index to check if there’s anything unusual.
Fixing the Common Canonical Issues
Typically, you can use two methods to fix canonical issues on your site
Implement a 301 redirect
Add canonical tags to your site’s pages. It tells Google the preferred page for similar-looking pages. Based on the issue you have to resolve, you need to choose the most suitable method.
Implementing Sitewide 301 Redirects for Duplicate Pages
This method is primarily used to resolves issues with HTTP/HTTPS and WWW/non-WWW
Implement a sitewide 301 redirect to the preferred URL version.
How to Set Up a Sitewide Redirect?
You can use several ways to set up a sitewide redirect. The most straightforward and least risky one involves setting up the redirect through the website’s host.
Start with searching Google for either “HTTP to HTTPS redirect [host name]” or “WWW to non-WWW redirect [host name].”
Find out if your host has a support page to explain the procedure to make the required change. Otherwise, contact and get help from your host’s support team.
If you are more resourceful and have developers to help you, ask them to set up your redirects. They may use:
.htaccess (Apache) redirects,
NGINX redirects,
With these changes, you will start noticing traffic and ranking changes. These changes are normal, but after a while, the site’s traffic and rankings will recover.
Add Canonical Tags to All the Pages of Your Site
This method is used for resolving the issues arising due to URLs changing according to user interactions (e.g., e-commerce sites)
In place of letting Google decide canonical pages for your duplicate pages, specify to the search engine which page you want to be considered canonical. Add a rel=canonical tag to all the site’s pages.
![]()
However, it can be highly inconvenient and impractical to add codes to every page of your site. The good thing is that various content management systems have several ways of making canonicalizing your site’s pages easier.
On WordPress sites, you can use the Yoast SEO Premium plugin to automate the addition of self-referential canonical tags to all your site’s pages.
HubSpot CMS allows the users to change their settings where CMS will automatically add self-referencing URLs.
Shopify will automatically add canonical tags to the site’s pages. That’s why site owners do not have to worry about the same.
3. URL Structure Issue in Website Technical Audit
The site’s URL structure should be as simple and self-explanatory as possible. A logical URL structure directly corresponds to organizing your site’s content. The URLs should be most intelligible to humans (URLs should use readable words and not long ID numbers). For example, if you’re searching for information about beagles, the following URL can help you decide whether to click that link:
http://en.wikipedia.org/wiki/Beagles
Three most common URL problems
You may see them on different websites. Read further to check if your site has one or more of these problems. We’ve also listed the solutions so that you can fix them as early as possible.
Problem #1: Non-www and www Versions of Site URLs
Sites with a www version and a non-www version for all its URLs will experience a split link value due to the same content on the two URLs. So, you will not get a 100% link value on the page that you want to rank in your search results. You could be getting a 50/50, 60/40, or other kinds of split link value between the two URLs with the same or similar content.
How to Fix?
- First, decide the URL style you want to use, www or non-www.
- Set up a 301 redirect so that all the links to your non-preferred URL style get directed to the right style. It will prevent the wasting of link value due to splitting between two URLs.
- Go to Google Webmaster Tools. Set your preferred domain. Now your search result listings will be consistent with your style preference.
- Use the preferred URL style to build links to your site.
Problem #2: Duplicate Home Page URLs
This is a more severe form of the earlier problem because it is related to your home page. You may have many URLs that go to your home page content. If you haven’t fixed the www and non-www duplication, the problem will be more pertinent and can lead to undesirable duplication. For example:
http://www.mysite.com
http://mysite.com
http://www.mysite.com/index.html
http://mysite.com/index.html
You may have fixed your website for non-www and www problems, but they may still have multiple versions of their home page. There may be sites with several versions and different extensions (.php, .html, .htm, etc.), like in the example above. It would lead to a great deal of duplication and wasted link value.
All these URLs lead to the same content. Now, the link value will get split into the four of them.
How to Fix?
- Set the URL http://www.mysite.com to be your main home page. 301 redirect all other URLs to this URL. Choose the most basic URL as your preferred URL (For example, if non-www is your preferred URL style, then do http://mysite.com)
- At other times, you require having different URL versions for tracking purposes or similar reasons. In such cases, you need to tell the search engine to select the preferred version. Set the version you want to show up in the search results.
- Link to the correct version of the home page URL while building links.
Problem #3: Dynamic URLs
It is a more complex and not-so-SEO-friendly problem shopping cart programs may stumble upon. Including various variables and parameters in your URLs can create an endless number of duplicate content and wasted link opportunities.
Here is an illustration. This set of URLs may lead to the same content:
http://www.mysite.com/somepage.html?param1=abc
http://www.mysite.com/somepage.html?param1=abc&dest=goog
http://www.mysite.com/somepage.html?param1=abc&dest=goog&camp=111
http://www.mysite.com/somepage.html?param1=abc&dest=goog&camp=111&id=423
Even if you rearrange their parameters, they may still show the same content. It can immensely waste the link value of the preferred page.
There are several reasons for the dynamic URL problem. Many companies have statistical purposes of using these as parameter-based URLs. It is necessary to ensure that you are aware of the SEO perspective during this exercise and take measures to fix it lest it affects your outreach or other desirable results.
Affiliates that give their unique ID to use in their links also face the dynamic URLs problem. For example, if you have 100 affiliates linking to a page, each linking page’s URL will be different as each affiliate owns a unique ID.
The Fix
Your site should use SEO-friendly base URLs. Choose a base URL that leads to content in place instead of a URL that uses other parameters. For example, http://www.mysite.com/unique-product.html is much better than http://www.mysite.com/category.php?prod=123 some generic category page is each linking page’s URL base.
- Choose a canonical tag that directs the search engines to employ the base version of the URL. In this way, you can use parameter URLs like http://www.mysite.com/unique-product.html?param1=123¶m2=423 > It will help you in retrieving your data. Moreover, the search engines consider the basic version of the URL as the official one.
- Make sure that you capture the data on the server-side. Subsequently, redirect the visitor to the correct URL while the data gets captured. Using various affiliate networks like ShareASale and CJ, you can carry out the task reasonably simply. Typically, the following parameters help you reach the right visitor links-parameters
Visitor visits the site; the server records parameter data
301 redirects the visitor to the right landing page
The takeaway here is that the visitor hardly notices the switch to the other website as it happens fast. It helps you get the data you need and ensures that the correct page gets the link value while visitors can see what they want.
4. Unnecessary Subfolders
Irrelevant subfolders can be a potential deterrent to your site’s ranking. Search engines will evaluate the importance of a URL based on how close it is to the root directory link. Therefore, it is advisable to remove the unrequired subfolders and subpages that go further away from the root directory. This will surely increase the traffic and the rankings to the search engine. The best tip is to use a minimal amount of subfolders to get an excellent hierarchical organization of the content.
 5. Unnecessary Subdomains
5. Unnecessary Subdomains
 5. Unnecessary Subdomains
5. Unnecessary SubdomainsA domain represents the human-readable version of the internet address of a website. Every website must have a unique domain. This is because the domain is the website address. Like every home in a state or a country has its unique address. Similarly, the domain must have it for easy access.
A domain can be quite complex as well, having multiple parts and multiple levels. You can personalize the domain as per your requirements.
How Does Domain Subheading Matter?

Why Do Companies Use Subdomains?
It is widely known that blogs on subdomains offer scanty SEO value. But, several companies still segment their website to include subdomains.
In other cases, companies may own very old websites. So, it may be truly hard to add content in any other way than to add subdomains.
Subdomains are also vital for big time-limited promotions. For example, during an event or otherwise, you think of creating a microsite to host a contest- “contest.website.com” The obvious benefit you get is that you can easily remove it as the contest is over.
A subdomain can also be a good option for pages you don’t expect to give you value in your link-building efforts. You can create temporary ones which you don’t need to rank for anything important.
However, subdomains are also good when you want to segment your audience. Let’s take the example of Craigslist, which offers localized content on newyork.craigslist.com. The apparent reason is that only people in those areas want to see the content. In other cases, when you have an international website and deal with audiences from various regions of the world, offering your content in different languages is made simpler with subdomains. Or you may also have to provide your other products at varying price points. Using the subdomain structure makes sense in such cases. However, make sure you talk to an SEO consultant if a subdirectory wot=uld be a better option.
6. Generic Folder Structure
Here are a few expert tips on managing a practical folder framework for digital asset management systems.
Placing SPACES & UNDERSCORES
When you use an underscore, space, or other special characters while naming a folder name, it will have specific ramifications. For example, placing the underscore or unique character at the start of the folder name forces the folder to “float” above the alphabetically sorted lists. But this trick can make way for several problems. Because it means the folder is not present in its usual place. Consider this if someone is browsing for the “Projects” folder, they will most probably not look for “_Projects’ ‘ folder at the top of the list. They may expect something in chronology like between the “Marketing” and “Research” folders. They may create the duplicate “Projects” folder that does not have the underscore in front.
FOLDERS & KEYWORDS Have a Deeper Relationship
Few tools and Digital Asset Management (DAM) systems generate keywords based on the folders in which the files are stored. Setting up your folder structure, think about keywords to be applied based on folder names. For example, if you have a file in a folder called “Business campaigns” inside the “Marketing” folder will appear in search results for “Business,” “campaigns,” or “marketing.”
To get comprehensive guidance on folder organization, access the free DAM Best Practices Guide.
Folders are POTENTIALLY REDUNDANT
You should avoid folders with overlapping categories. If you have a folder named Staff and another folder named office, you do not want to include staff information in both folders. It would help to create more specific folders. Or eliminate one of the two or place one folder inside the other folder. For example, the “staff” folder could go inside the “office” folder.
EMPTY SUBFOLDERS “TEMPLATE.”
Keep an open group of folders and subfolders for a ready template. This will help in having subfolders that can be used across the folder structure, especially if you create folders requiring a common group of subfolders in the future. It will help you in getting things sorted and done quickly. All you need is to copy and paste the template of subfolders into new folders. You do not have to create each subfolder manually.
Sort out VERY DISORGANIZED FOLDER STRUCTURES
If things seem too messy, start fresh to build a new well-planned folder structure. Just move the existing items to the right place in a new structure. Or choose a cutoff date when the old location transforms into a read-only archive. No changes get copied to the new location.
7. Tracking Parameters in the URL
The piece of code added to the end of a URL is known as the tracking parameter. It can then be separated into its components by the system backend for sharing information contained by that URL.
Some of the main groups of parameters to work with include:
Campaign parameters
Redirect parameters
Additional parameters.
Why are Tracking Parameters Important?
If a user clicks or views the ads, the advertiser seeks the information about the click or view. With a well-maintained record of such data, one can transfer the information about the interaction, helping to accurately measure the performance of that ad. Using the tracking parameters, you can capture snapshots at the time of the click. Also, you need to share the information that the campaign sparked the click. Also, look how the network served an ad to attract clicks and more.
What are the Benefits of Tracking Parameters?
Various parameters allow you the right level of specificity in reporting. They offer a space to provide the best levels of granularity to the captured information. This parameter helps to create a place where labels are attached to data. It enables the knowledge to get shared between systems. It also allows the information to be separated in a way allowing the humans to understand it.
What are the Types of Tracking Parameters in Technical SEO Audit?
A campaign parameter offers four levels of granularity using a tracker to provide a ‘space’ that helps to comprehend why a click or impression was done. Apart from that, these parameter spaces also capture the values with ‘creative,’ ‘campaign’ or an ‘adgroup’ for tracking parameters. The four spaces help to store information. One can drill down the data to get a greater context.
For redirect parameters, you can specify where the user must end up following an ad click. With a knowledge of the default tracker behavior, the user ends up at an app store page for your app. But perhaps you want a user to instead arrive at a landing page outlining a promotion? You would want a user to get a deep link directly on the product page within your app. This will help you to accomplish the redirect parameters. You have three redirect parameters for
Redirect
Fallback
Deep-link
These are parameters that will be powerful tools for driving conversions and enhancing UX.
On the other hand, additional parameters will also impact. The label parameter helps you to take care of all the additional information you require to transfer. But, it shouldn’t fit in a defined space like the one discussed earlier. Make sure that you also include additional cost parameters that allow you to track ad spend. You also need a referrer parameter that stores information about the referral programs in the server-to-server parameter. It enables an Ad Network to take care of the redirect to the store directly.
8. Session IDs in the URL
A session ID (SID) is a unique number a server assigns to the requesting clients. The word ID stands for an identifier that helps to track and identify user activity. The unique ID may be a numerical code, number code, or alphanumeric code. Technically, a session can be a temporary connection between a server and a client.
For search engine optimization (SEO), session IDs are a relevant topic for certain circumstances. And they can lead to problems like duplicate content.
Avoid Using Session IDs in URLs to Improve Your Search Ranking
Do not use Session IDs that will make search engine life interesting. A session ID will identify a particular person visiting a site at a particular time. It keeps track of the pages the visitor looks at and the actions the visitor takes in a session.
While requesting a page from a website, the server will send the page to the browser. As you request another page, the server will send that page also. However, the server is not aware if you’re the same person. Moreover, the server requires knowing who you are. This will help the server to identify you each time you request a page. The server does that with the help of session IDs.
Session IDs are used for various reasons. However, the primary purpose of a session ID is to allow web developers to create several types of interactive sites. Creating a secure environment, the developer can force visitors to visit the home page first. In other cases, the developers would like the visitor to resume an unfinished session.
A few systems can also help you to store the session ID in a cookie. But, the URL session ID of the user’s browser may be set not to accept cookies. An example of a URL containing a session ID:
http://yourdomain.com/index.jsp;jsessionid=07D3CCD4D9A6A9F3CF9CAD4F9A728F44
A search engine may recognize a URL included in a session ID. However, it probably won’t read a referenced page because whenever the search bot returns to your site, the session ID expires. The server will therefore do one of the following:
Display the error page in place of the indexed page. It is better to display an error page in place of an indexed page. Better still, go to the site’s default page. The search engine will index a page that is not present in session if someone clicks the link on the search results page.
Assign a new session ID. The URL that the searchbot originally used will expire; the server will replace the ID with another session and change the URL. Consequently, the spider will be fed multiple URLs for the same page.
If a search bot reads a referenced page, it may not index the same. Webmasters complain several times that search engines enter their site to request the same page again and again. However, the bot ultimately leaves without indexing the major part of the site. This is because the search bot gets confused due to the multiple URLs and leaves. At other times, the search engine does not recognize the session ID in a URL. If a client has thousands of URLs indexed by Google that are a part of the long-expired session IDs, they point to the site’s main page.
In the worst-case scenarios, the important search bots of a search engine will recognize session IDs to work around them. Apart from this, Google recommends that to use session IDs, you should employ a canonical directive to the search engines for the appropriate URL for the page. If you are using multiple session IDs, and your URLs look somewhat like this:
http://www.youdomain.com/product.php?item=rodent-racing-gear &xyid=76345&sessionid=9876
Hundreds of URLs can be effectively referencing the same page on the search engine. Use your section of web pages to put a tag on the correct page to tell Google about the page it should crawl.
Display
Session ID problems are now quite rare than they were earlier. Fixing a session ID problem helped sites that were invisible to search engines to get visible all of a sudden! Removing session ids can sometimes work like a miracle to fix a huge indexing issue.
you can do some more things if your website has a session ID problem apart from the canonical directive:
Use a cookie on the users’ computer to store session information. The server can check the cookie every time a page gets requested. It helps to check if the session information gets stored there. However, the server shouldn’t require cookies, or you can run into further problems.
Make sure that your programmer can omit session IDs when a search bot is requesting a web page. The server will deliver the same page to the search bot, but it does not assign the session ID. A search bot can travel throughout the site without the need to use session IDs. The process is used for agent delivery. Here, the word ‘agent’ refers to the device, which can be a browser, searchbot, and other programs requesting a page.
9. Broken Images in Technical Site Audit
Several broken images may also cause the same issues, like broken links, that we need to look at in greater detail. You will get broken links that are no good as they are dead ends for search engines. Moreover, this issue also leads to the search engines downgrading your website and lowering its visibility as they lead to a poor user experience.
How to Detect Broken Images on Your Website?
The easiest way to find broken links is using a special tool. Some of the highly effective common tools include Broken Link Checker and Free Link Checker.
“Site Audit” can offer you a detailed report about broken links and graphics. Tools like Xenu and Netpeak Spider are desktop programs that can help you get a non-existent link check. You can get the required report as you simply type your website address in any of these services to click a button:
10. Broken Page Links
Your website is a special asset where you need to put a lot of effort to ensure that it gets a lot of traffic. When your links are not working, it will take away all your hard work. They ruin your SEO efforts. Broken links will lower the flow of link equity throughout the site that can impact the rankings negatively. Being a top SEO Technical Audit Services Company, our team can offer the most comprehensive way to find and fix broken links.
You must check the broken links periodically on your website. Here is a step-by-step guide to helping you find and fix broken links present on your website.
Must Read: Broken Link Building Guide
Step 1: Track Broken Links
Several tools can help you to identify broken links. Google Analytics is one of the primary tools used for this purpose.
Google Analytics is one of the best free technical SEO audit tools to track website performance. It is instrumental to finding the broken links easily. Log onto your Google Analytics account. Click on the Behavior tab. Select “Site Content” followed by “All Pages.”
Set the evaluation period to check the data for the amount of time you want to check. For example, you want to check your broken links every month, set the period for a month after your last check.
You will see all your viewing options that are going to set everything to the default pages. Make sure that you select Page Title instead.
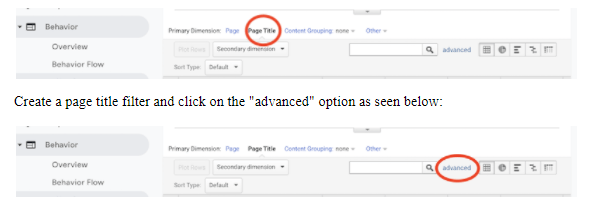
In the “advanced” window, set up the filtering that will go like this.
Include >Page Title>Containing>”Your 404 Page Title,”
Click on “Apply.” It will present before you one or more page titles having the same name as the one depicted below for a one-month range.
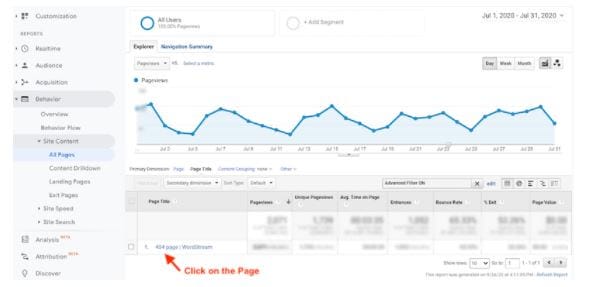
As you click on the page title, you will see the various broken results on that 404 page. With a full-screen view, you can find the frequency of 404 error has occurred 2,071 times. As you reach the button of the page, you get more information as it has happened through 964 pages:
Export this report to a spreadsheet. Now you can proceed with fixing the links. You must know of all the places the broken links occur on your website. You may also have to set redirects to land on the intended page.
Step 2: Create a Report and Track Your Changes
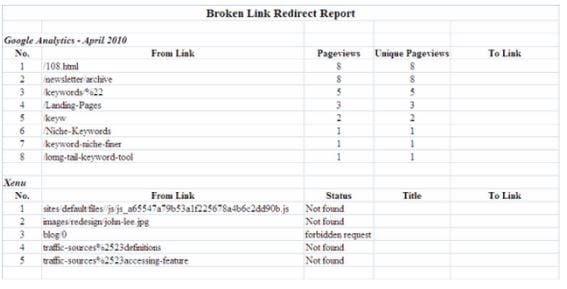
You have the list of the broken links on the spreadsheet you’ve exported. Create columns on the excel spreadsheet to track link redirect processes. You will now have a Broken Link Redirect Report. Keep the data for broken links, page views, and unique page views in your Excel sheet.
As you export the data from Google Analytics, export it from Xenu as well. Now, organize the primary data from Google Analytics and Xenu into separate sections on your Excel spreadsheet.
Step 3: Decide Pages You Want to Redirect
Now, the preparation is done. Next comes the stage of analyzing. Google Analytics and Xenu offer you a list of links that can be broken. Now decide about the pages you want to redirect. But before you redirect them, make sure that you analyze the pages to discover why they are not working correctly.
From the Google Analytics section of the short sample above, we can see that not all broken links are created equal. It is important to understand that all broken links are created equal. Few links are visited quite often, and others are not visited in the same way. There can also be URLs due to human error. These are stray broken link URLs that you will visit only once. It is not worth fixing these kinds of URLs with a stray visit or two. But you must pay full attention to improving the broken links with multiple visits to fix them even if they are produced out of human error).
One can figure out the correct URL and fill the data in the spreadsheet for a few links. In case you go for other links, use a tentative URL and highlight it with a different color; you can link the other URLs to redirect them to the domain homepage. Conclusively, you just need to redirect the links with several visits and those ones having an error-causing rule.
The Xenu report does not display URLs recorded in your Google analytics due to typing errors. Xenu shows only the actually existing links that are live on the site. However, the URLs may still have certain character errors. We must identify these instances and dig out the reasons for the error. Only after this can you fix the problem in the most practical manner.
This step accomplishes your task once you’ve placed the links that must be redirected; document them all in your Broken Link Redirect Report.
Step 4: Redirect in CMS
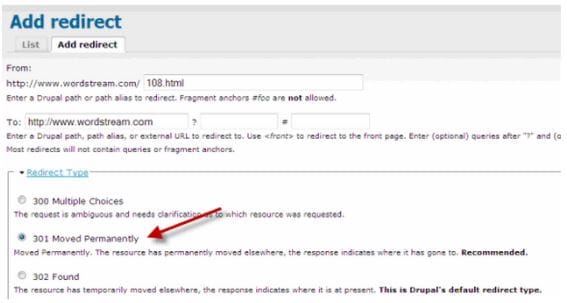
Here is an account of how you will redirect the links in your content management system. Let us use WordStream’s Drupal CMS as an example.
Access Administration – Site building – and then URL redirects. Add redirect. Fill the “From” and “To” blanks as you copy and paste the coveted link from your final Broken Link Redirect Report. Make sure that you notice the link format during the process. Choose “301 Moved Permanently” in your drop-down menu of the Redirect Type. Click “Create new redirect”.
Repeat the process to take care of all the broken links. Update the Broken Link Redirect Report.
Now you can experience more pride for your website as ALL your links work to help the users.“ The search engines are happy!
More on Broken Page Links
As we already discussed, broken links include web pages that users cannot find or access for several reasons. Web servers will return an error message if the user tries to access a broken link. Other ways to address broken links are known as “dead links” or “link rots.”
Broken Link Error Code
Here are few error codes a web server can return for a broken link:
404 Page Not Found: It gives the information that the requested page/resource is not present on the server.
400 Bad Request: It indicates that the host server is unable to understand the page’s URL. It marks the following:
Bad host: Invalid hostname: In this, the server name does not exist or is not reachable.
Bad URL: It is also addressed as a Malformed URL and may result in an extra slash, missing bracket, wrong protocol, etc.
Bad Code: It indicates an invalid HTTP response Code: The server response violates the HTTP spec.
Empty: The web server gives “empty” responses displaying no response code or no content.
Timeout: It occurs in the form of HTTP requests that get constantly timed out in the link check
Reset: In the reset option, the host server drops connections. It is busy processing other connections or gets reprocessed.
Why Do Broken Links Occur?
There are so many reasons why broken links occur, for example:
If the website owner enters the incorrect URL ( like misspelled, mistyped address, etc.).
If the URL structure of the site changes to (permalinks) without a redirect, causing a 404 error.
When the external site is no longer available, it becomes offline or gets permanently moved.
It also links to content (PDF, Google Doc, video, etc.) that has been moved or deleted.
interference due to Broken elements like HTML, CSS, Javascript, or CMS plugins.
Geolocation restriction not allowing outside access.
As we discussed earlier, broken links will affect the Google Search results. But, this wouldn’t impact the overall SEO. It is only if you have many broken links on a single page, it will indicate that the site is abandoned. The Search Quality Rating Guidelines use broken links to find out the quality of a site, but if you’re constantly checking the broken links or fixing them, it will help maintain the site’s quality.
11. Switchboard Tags
Much like canonical tagging, switchboard tagging is used to alert Google about another page similar to where the tag is located. It enables Google to index and rank the switchboard tags appropriately. One does not have to use them as separate sites that have the potential to affect your site’s rankings negatively. The specific tag is usually “bidirectional.” It is used on the desktop version and the mobile version.
At this link of Google Developers, you can find out what a tagging system usually looks like.
It means that you can place a similar tag similar on the desktop version of the website:
<link rel=”alternate” media=”only screen and (max-width: 640px)” href=”http://m.example.com/page-1″ >
However, you can place a tag like this one on your mobile version.
<link rel=”canonical” href=”http://www.example.com/page-1″ >
You need to implement both tags to make them work. If you have a mobile version of your site, you will surely want to take advantage of the switchboard tags. It offers a simple solution for a quick edit to help both versions of your site for their indexing and rankings.
12. Missing Breadcrumbs
Breadcrumbs (or breadcrumb trail) is the secondary navigation system. It displays a user’s location in a web app or a site. There are different types of breadcrumbs and the commonest ones include:
Hierarchy-Based Breadcrumbs
This is the commonest form of breadcrumbs that are generally used on a site. The breadcrumbs inform you about the site structure and the several you need to get back to the homepage. It can often be a sequence like this: Home > Blog > Category > Post name.
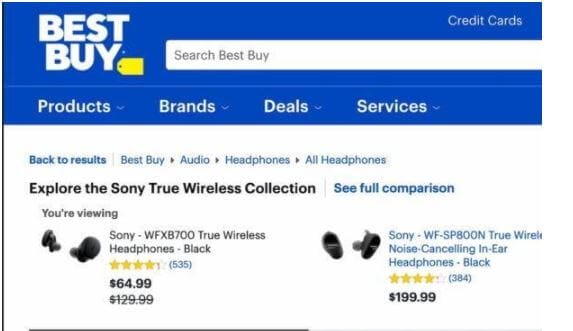
Best Buy gives you a good idea of where you are in the audio department
Attribute-Based Breadcrumbs
You will find these types of breadcrumbs on e-commerce sites, where the users search, leaving a the breadcrumb trail is made up of product attributes. for Example: Home > Product category > Gender > Size > Color.
History-Based Breadcrumbs
History-based breadcrumbs carry out exactly what it says. You can order them as per your activities on the site. They will be seen somewhat like this- Home > Previous page > Previous page > Previous page > Current page. See Macy’s site example below to learn how you can make them function.
 13. 404 responses without proper 404 page
13. 404 responses without proper 404 page
 13. 404 responses without proper 404 page
13. 404 responses without proper 404 pageThe 404 error (HTTP 404) is also known as a “header response code” or “HTTP status code” or just a crawl error. It corresponds to the “Not Found” or “Page Not Found.”
Check the definition for 404 errors below.
“The server has not found anything matching the Request-URI. No indication is given of whether the condition is temporary or permanent. The 410 (Gone) status code SHOULD be used if the server knows that an old resource is permanently unavailable and has no forwarding address through some internally configurable mechanism. This status code is commonly used when the server does not wish to reveal exactly why the request has been refused, or when no other response is applicable.”
– via w3.org
Put simply; it means that code tells users and the search engines that the requested URL or the resource being referenced literally cannot be found.
Imagine a robot giving a shrug and a blank look.
There can be varied kinds of response error types. Most URLs will return a response code of one sort or another. A correctly functioning page returns a “200” status code, which translates to “Found” in the computer language. The other response codes include the “server errors,” which include the HTTP status codes 500-599. Webmasters can diagnose the different error types going to the source of the errors to fix it appropriately.
404 errors is the common error type. They are generally handled incorrectly by even knowledgeable people. A 404 HTTP error is also known as a Client Error. The user’s web browser (Google Chrome, IE, Firefox, etc.) is addressed as the client here.
Occurrence of 404 Errors
A 404 error can occur in several conditions. For example, if a page has been removed or moved to a different website section and it stands nonexistent or like a deleted page that is forgotten and not redirected)
If a webmaster, or a software engineer mistypes the URL on a page or a “page template” or ends up with a copy-and-paste mistake (using a wrong URL link).
When web pages, social media posts, or email messages get broken links or accidentally truncated links.
The best type of soft 404s occurs when a page issues a 200 (OK) status in issuing the right kind of error for something that went wrong. In these cases, websites could issue 404 errors, but they do not. It indicates that 404 errors on the page are not working properly. At times, 404 errors can function in one part of your website but not in others.
Are 404 Errors Good or Bad for Search Engine Optimization (SEO)?
Practically, 404 errors are “bad” as they display errors on your website or on your web, relating to your website.
It is not hard to understand that a user coming across a 404 page will not want to return to that site later.
If a site has a lot of 404 header response errors or other errors like 403s, 500s across it, that can create a higher overall error rate versus success rate.
When Google finds many errors, like 404 errors compared to available pages, it can result in a lot of trust issues. It won’t like to send customers to your site. Google rates websites based on user experience and if a website is just full of errors, it gives users a bad experience. Google will likely downgrade your site for the trust issues.
If your website is linking to many non-functional pages, you are passing SEO equity into a void. It’s just like a purse with many holes in it; the money you put in is the money that drips out of it.
However, 404 errors will keep happening no matter what. But, the important thing when these errors do occur, they should be properly functioning. They must notify you that the 404 error occurred and its location. With this information in hand, you can go about fixing the error with a permanent 301 redirect. Keep in mind that the user and search engine should not have to face this issue again.
404 is seen as a bad error by few teams more than others. But the reality is errors will occur if you do not listen to the messenger” and want to correct the mistake; a 404 error ode will help identify that. It is necessary to issue a proper 404 status code to find issues and fix them easily. It’s only the unfixed 404 errors that will be potentially bad.
14. Bad URLs Do Not Return 404 Status Code
The web server should show you a 404 page. But you won’t find it’s you click on it. However, the functionality of the 404 code is not restricted to this alone. It will also tell the Google Bot where the document really exists. It means the page should return the appropriate HTTP status code or else it is defective.
How Do I Return the Correct HTTP Status Code for a 404 Error Page?
Content-Management-System or the web servers are generally not set up correctly. This leads to an error in the page that returns to either the HTTP status code 200 (OK) or a 301-redirect (sending the user and Google-Bot to another page). This will be a defective 404 page.
This article finds out information on the correct configuration of a 404 error page having an appropriate HTTP status code 404. It tells you the difference between:
A static 404 error page with the use of the .htaccess file and Apache webserver
The 404.php file and WordPress CMS in the theme-directory
15. Are the Session IDs of your Site Functional?
A website assigns a session ID, also known as a session token, to keep track of visitor activity. This is a unique identifier parameter for a specific user. It has a predetermined duration of time or session,
Two common uses for session IDs
User authentication
Shopping cart activity
One can use a standard method of delivering and storing session IDs with cookies; but, it becomes less feasible because a session ID also gets embedded in a URL in the form o a query string. And URL parameter session IDs and the Cookie impact the proper crawling and indexing of the content by the web search engines.
What happens in Session IDs Using Cookies?
Typically, cookie-stored session IDs are more secure as compared to the ones transmitted via URL parameters.
That said, an issue arises as Search engines ignore cookies.
But you can solve it.
This is how.
Provide alternative pathways to search engines to access web pages if you are using cookies to present content, either in the sitemaps or direct links.
To find out if cookies are preventing the bot from crawling your page, “Fetch as Googlebot” related to Google Webmaster Tools account,
URL Parameters for Session IDs
You can use URL parameters for session IDs. It will help in tracking visits or referrers. In such a case, you have to append the identifier to the URL.
The glitch that arises here is that new URLs created for an existing web page give rise to content duplicity issues. Check the URLs that point to the same content:
http://www.example.com/products/women/dresses?sessionid=66704
http://www.example.com/products/tools?sessionid=45365
http://www.example.com/products/tools?sessionid=45365&source=google.ca
How Can You Deal With This?
Here’s how.
Use canonicalization (described in detail in the article), whereby you tell the search engines the correct version of the URL you want to index.
Moreover, Google offers a URL parameters tool in its ‘Crawl’ section of Webmaster Tools. Using this, you can instruct on how Google must handle URLs containing parameters.
16. JavaScript Navigation
JavaScript Navigation is an essential part of technical SEO is JavaScript SEO. It involves making JavaScript-heavy websites search-friendly, enhancing their crawlability and indexability. The ultimate goal is to make the websites rank higher and get more visible in the search engines.
Many consider JavaScript bad for SEO. But is it true that JavaScript is evil? Not at all. It’s quite different from what most SEOs professionals are used to handling. But by putting in a slight effort, you can learn much.
Javascript is not perfect, and it may not always be the right tool for the job. But if you parse it more than you should, it can result in heavy page load and low performance.
How Google Processes Pages with JavaScript
Earlier on, a downloaded HTML response could let you see the content of most web pages. However, with an increase in JavaScript, search engines must develop several pages like a browser to find out how a user sees the content.
Web Rendering Service (WRS) of Google is responsible for processing the rendering of pages. This image tells how Google covers the process.
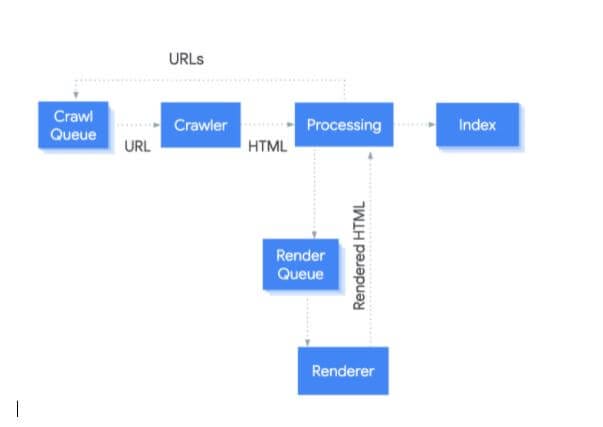
Start the Process at a URL
First of all, the crawler comes into the picture:
Crawler Action
The crawler will send GET requests to the server, which response with headers and the file’s contents.
Google prefers mobile-first indexing, the request generally comes from a mobile source or user agent. Use the URL Inspection Tool in the Search Console to check and find out how Google crawls your website. Run the URL on the too; check coverage information for “Crawled as,” you will know if you are still on the desktop indexing or mobile-first indexing.
In this case, the requests are coming from Mountain View, CA, USA, but they will also do some crawling for locale-adaptive pages outside of the United States. But few sites will block visitors from specific countries or the ones using specific IP in various ways. This could imply that the Google bot cannot see your content.
Few sites can also employ user-agent detection to display content to various kinds of crawlers. Especially for the JavaScript sites, Google could see things as being slightly different than a user. The URL Inspection Tool present in Google Search Console provides for Rich Results Test and Mobile-Friendly Test. These tests are important for handling JavaScript SEO issues. They offer you information on what Google considers important for checking. For example, if Google is blocked, and they can still see content on your page. You will find more information about this in the section on renderer as there are vital differences in the downloaded GET request, the rendered page, and the testing tools.
Moreover, it is worthwhile to note Google may state the output of the crawling process for “HTML” as illustrated in the above image. However, Google is crawling and storing all their sources required to build the page, whether they are Javascript files, CSS files, HTML pages, XHR requests, API endpoints, and more.
Processing
Understanding the term processing mentioned in the various systems is essential. Read further to know about the several aspects of processing related to JavaScript.
Resources and Links
You need to understand that Google does not navigate from page to page like a random user. Instead, one part of the processing checks a page for its links to the other pages or files required to build a page. In many instances, Google pulls out the links to add them to the crawl queue, which is Google’s tool for prioritizing and scheduling crawling.
Google is also likely to pull resource links (CSS, JS, etc.) used for building a page from sources like <link> tags. But the links to other pages should be present in a specific format so that Google treats them as links. The different internal and external links must have a <a> tag with an href attribute. You can help the process proceed in several ways for the users with JavaScript that are not search-friendly.
Good:
<a href=”/page”>simple is good</a>
<a href=”/page” onclick=”goTo(‘page’)”>still okay</a>
Bad:
<a onclick=”goTo(‘page’)”>nope, no href</a>
<a href=”javascript:goTo(‘page’)”>nope, missing link</a>
<a href=”javascript:void(0)”>nope, missing link</a>
<span onclick=”goTo(‘page’)”>not the right HTML element</span>
<option value=”page”>nope, wrong HTML element</option>
<a href=”#”>no link</a>
Button, ng-click, there are many more ways this can be done incorrectly.
The internal links added with JavaScript do not get picked up till rendering has been done. Therefore, the rendering must be quick and not become a cause for concern in most cases.
Caching
As Google downloads files of different kinds, including JavaScript files, CSS files, HTML pages, they will be aggressively cached. Typically, Google ignores your cache timings and fetches new copies when it wants. You will understand more about this in the Renderer section coming ahead.
Duplicate Elimination
When crawlers find Duplicate content, Google will eliminate or deprioritize it from the downloaded HTML in rendering. With the prevalent use of the app shell models, small amounts of content, you might find a code that may result in the HTML response. Every page on the site will show the same code.
Moreover, this code can also be shown on multiple websites, giving an idea of the pages to be treated as duplicates. This means that the pages would not immediately go to render. And there can be greater implications like a wrong page or the wrong site may display in search results. However, the chances are that it resolves by itself over time. This can, however, be problematic, especially for newer websites.
Most Restrictive Directives
Google will choose highly restrictive statements between the rendered version of a page and HTML. If JavaScript changes a statement and that conflicts with the statement from HTML, Google will simply obey whichever is the most restrictive. Noindex will override index, and noindex in HTML will skip rendering altogether.
Render Queue
Every page goes to the renderer now. One of the biggest concerns from many SEOs with JavaScript and two-stage indexing (HTML then rendered page) is that pages do not get rendered for days or sometimes even weeks. According to Google, pages reach the renderer at a median time of 5 seconds. The 90th percentile was minutes. Thus, the amount of time between getting the HTML and the rendering of the pages generally is not a cause of concern.
17. Flash Navigation
Flash navigation is created to catch the immediate attention of the site’s visitors. It is found to work in many cases. However, the real question is whether flash navigation can get the search engine’s attention? Flash is generally used for slideshows and flash movies present on technological sites. It displays multimedia content on art and entertainment sites. Websites requiring search visibility are popular on web and flash websites. However, the flash elements on a website were unreadable by the search engine crawlers until June 30th, 2008, when Google announced its improved capability for index flash files for including them in their search results.
However, Flash websites or flash elements on websites also have other problems. For example:
No Inner Page URLs: If your website is built on Flash, it will be just one URL: the home page URL. With proper internal page links, you get very few opportunities to let your flash website show up in search results.
Slower Page Loading Times: Complete flash websites with a lot of flash content typically load slower. This problem will significantly reduce with better internet download speeds and browser compatibility.
Poor User Experience: Flash navigation websites are unconventional. They force the user to spend more time finding the right content on a flash website. If the site offers a compromised user experience, it becomes hard to rank the website high in the search engines like Google.
Indexed by Google Bots Only: Google is a search engine that officially indexes Flash. The search engines are text-based and index sites according to the HTML content. However, there can be glitches in Google indexing the flash websites.
Poor On-Page Optimization: Typically, flash websites or flash elements do not have on-page SEO elements like a header, image alt tags, meta title, meta description, and anchor text tags.
No Link Value: Search engine crawlers are unable to crawl links present in the Flash. A completely flash-based website may have only one link, such as a home page, and no internal page links. That’s why you do not get any link value for flash-based websites.
Hard-to-Measure Metrics on Google Analytics: Flash-based websites cannot track user behavior on the site. It is hard to understand the site performance metrics of flash-based sites.
According to research, more than 30 to 40 percent of websites use Flash. But, still, these sites get organic traffic from search results. At the same time, some of the flash sites belong to big brands that get popular by several other modes, such as offline marketing. Thus they get many natural links to their site. This naturally improves their search engine ranking. But other not-so-popular sites must incorporate SEO into their flash-based websites to optimize the site for search engine indexing.
Here are a few quick tips for entirely or partially flash sites that need to use SEO for a well-optimized site that grabs Google’s attention.
Use Multiple Flash Files
First of all, do not get your complete website designed in Flash. As discussed, it makes it difficult for sophisticated Google bots to index the site. Instead, split the distinct flash content into several separate files in place of a big file.
Add HTML Element to Flash Files
Search engine crawlers look for text content, and the HTML text is in a highly readable form than the one embedded in flash files. Moreover, Flash does not display external links like HTML. So, you must add HTML format content to your flash files. This will help these files to get seen by search engine bots. As stated earlier, flash files will do better when these are segregated into separate files. Each flash file must have a corresponding HTML page.
You should embed the flash files in the HTML while adding descriptive data to the site. This includes adding page titles, headers, image alt tags, anchor text, and metadata. In general, it can be advisable to avoid Flash as much as possible and also ensure using HTML for the most important elements of the site. Use regular text links as much as you can. Check the sample of two flash objects embedded in HTML for facilitating search engine indexing.
Optimize Flash Sites for All Browsers
While you optimize your flash website for SEO, do not forget that usability is another factor that must be taken into account while building flash-based websites. You can get an enhanced user experience. It will be an important factor for the search engine optimization of the sites. It is important to optimize the flash-based sites for your browsers to give enhanced usability. Use the Scalable Inman Flash Replacement method (slFR) or the SWFObject Method to learn more about the flash content into simple vanilla if a browser does not support Flash.
Avoid Using Flash for Site Navigation
Make sure that Flash should not be used for navigation on the website for two important reasons. The first reason is to avoid confusing navigation options. Improper navigation will interfere with the site’s usability. Secondly, the web analytics that tracks and measures your site’s performance does not give accurate data. It can be hard to measure the data, like the visited pages and also the parts of the site with a higher viewership. It also helps to track the stage when the visitor abandoned the site on flash-based sites.
Importance of Proper Sitemaps in SEO Technical Audit
Sitemaps facilitate the indexing of several pages by search engines. In the case of websites using Flash, it is important to use XML sitemaps. They are created to put them into the root directory.
The takeaway is that you should avoid using completely flash-based web designs because they are hard to be crawled and indexed.
And always build corresponding HTML pages for the flash pages of your website. This will allow for the easy indexing of your website, allowing your website to show up in search results for your keywords. If you’re using Google Analytics for tracking the performance of your site, then you must enhance the tracking of the flash elements by setting up special goals and funnels.
18. Images Used in Navigation
It is necessary to correctly use the images as this will help readers to get a better insight into your article. Though Google gives greater importance to the text, it also counts the images you have used. Your users will certainly appreciate getting a summary of what you are looking for in a chart or data flow diagram or get attracted to the attractive images on your social media posts.
Adding relevant and appealing images to all articles you write will prove helpful.
It will also make them more appealing. But you should also optimize the alt text of your images. The images are important for making your visual search increasingly important. You can see this in Google’s vision for the future of search. It will help to increase your organic traffic. Having visual content on your site makes complete sense to enhance your SEO. Therefore, you must place image SEO as a priority in your to-do list.
Finding the Right Image
It is better to use original images, like your product images or your photos of yourself or your workplace, in place of using stock photos. Having a team page with the pictures of your actual team will count greatly in increasing the authority and the trustworthiness of your website.
Your article requires an image in tune with its subject. Do not just go on to add a random photo to get a green bullet in your Yoast SEO plugin’s content analysis. The image you choose must:
Reflect and relate to the topic of your post
Place the image near the relevant text.
For the main image that you’re trying to rank, keep it near the top of the page, but it should not feel forcibly placed.
Images placed with related text rank better for the keyword they are optimized for. Let us find out about SEO images as we proceed further in this article.
Scale for Image SEO
Page Load speed is an important characteristic of user experience. Loading times are highly important for UX and SEO. The faster the site, the easier it is for search engines and users to index and use its pages. The pixels of the images can have a great impact on the loading time of the site. When you upload a large image to display it is really small; for example, in a 2500×1500 pixels image displayed at 250×150 pixels size, it stalls the loading process of the entire website. Therefore, resize the image and choose how you want it to be displayed. WordPress will help you to do this automatically as it offers multiple sizes of the image after you upload it. However, this does not mean that the file size is optimized as well. Take care of the size in which you upload your images.
Use Responsive Images
Most of the users access your site on their mobile devices. It means all your images on the website should be responsive. It will be readily done for you in WordPress as it was added by default from version 4.4. Moreover, the images must have the src set attribute, making it possible to serve a different image according to the screen width of the mobile devices.
19. 302 Redirects
A 302 redirect is one of the temporary redirects that helps users and search engines to land the desired page for a particular amount of time until it gets removed. It will be displayed as
302 found (HTTP 1.1)
Moved temporarily (HTTP 1.0).
A 302 redirect is done using a meta tag or JavaScript. So, there is less time spent on it than a 301 redirect which requires accessing server files taking additional time and effort.
Webmasters also prefer 302 redirects rather than 301 redirects. A few people hope to avoid Google’s aging delay related to a 301 redirect. But you must know the utility of both the redirects and only then use them appropriately because improper use can become an issue for the search engine. Google then might have to consider if the applied 302 or 301 redirects were meant to improve the search engine experience.
Many times, Webmasters simply use a 302 redirect when a 301 redirect was needed, just because they did not know about the difference. It can negatively impact your search engine rankings. Additionally, there can be problems like continued indexing of the old URL, and it may also lead to division link flow between several URLs.
When Should a 302 Redirect Be Used?
Knowing when to apply a 302 redirect is important. Use a 302 redirect for:
A/B testing for a webpage’s functionality and design.
Getting client feedback for a new page without having an impact on site ranking.
Updating a web page while providing viewers with a consistent experience.
Broken webpage, and you want to maintain a good user experience in the meantime.
302 errors are temporary redirects that are used if webmasters want to assess the performance or gather feedback. The redirects are not used to give a permanent solution
20. Meta-Refresh Redirects
We have talked about various web server redirects. But there is another category of redirects known as meta refresh redirects. This is a client-side redirect, unlike 301 and 302 redirects that will occur on the web server. A meta refresh redirect will instruct the web browser to reach a different web page within a specified time.
Example:
<head>
…
<meta http-equiv=”refresh” content=”4; URL=’https://ahrefs.com/blog/301-redirects/'” />
…
</head>
Meta refresh redirects are generally seen in the form of a five-second countdown with text that goes like “If you are not redirected in five seconds, click here.”
Google claims to treat the meta refresh redirects or other redirects; you are not recommended to use these, barring certain special cases.
For example, if you are using a CMS periodically to overwrite your .htaccess file. You can also redirect a single file in a directory using multiple files. Sometimes, a meta refresh redirect may lead to a few issues. For example,
It can confuse the users. If a redirect happens too quickly (like within 2-3 seconds), and the users of the browsers cannot click the “Back” button. Moreover, the users may experience page refreshes they did not initiate. This can be a cause of concern for your website’s security;
Meta refresh redirects may also be used by spammers to disorient search engines. If you use them quite often, search engines can consider your website being spam and deindex it.
The meta refresh tag does not contain a significant amount of link juice.
Thus, if it is not specifically needed on your pages, you can use a server-side 301 redirect in its place.
21. JavaScript Redirect
A JavaScript redirect offers an optimal way of redirecting because search engines need to render a page to get a redirect. Redirecting using a 301 redirect is always recommended (except if you’re looking to temporarily redirect).
JavaScript redirects are typically picked up by search engines, and they will pass authority.
If you do want to use JavaScript redirects, please be sure to receive consistent signals.
It will include the redirect target in the XML sitemap.
Allow for updating the internal links for pointing to the redirect target.
You can also update the canonical URLs for pointing to the redirect target.
Ways to Implement JavaScript Redirects
There are methods to recommend a function to redirect like with window.location.replace().
You can get an example of what a JavaScript redirect asunder:
<html>
<head>
<script>
window.location.replace(“https://www.contentkingapp.com/”);
</script>
</head>
</html>
This code sends the visitor to https://www.contentkingapp.com/ after the page loads.
The biggest benefit of using the window.location.replace function is that the current URL does not get added to the visitor’s navigation history. On the other hand, the popular JavaScript redirect window.location.href gets added. It can lead to a visitor being stuck in the back-button loops. Thus, don’t use Javascript redirect to redirect visitors to another URL immediately.
<script>
window.location.href=’https://www.contentkingapp.com/’;
</script>
22. Broken JavaScript & CSS Links
It’s no secret it requires a lot of hard work to run the site. It means that you must fix broken links as you find them. Otherwise, it can prove detrimental to all the hard work you have done earlier.
The problem of broken links can be a lot worse with outbound links. You will not be getting notified of the change in your linked website. Therefore, you should have a daily check to see whether all of your links are still working.
Broken Links Can Be Very Harmful to Your Site in Two Ways:
Destroy user-experience. When users find a dead-end link like 404, they feel annoyed.
Bring down the SEO effort. Broken links will curb the link equity flow on the site that will have a negative impact on the rankings.
Make sure that you prevent these kinds of broken links on your entire site. Read the possible solutions further.
Why Broken Links Are Bad?
Broken links create an impression of callousness. If the users get a 404 Page error, they will think as if you don’t take your website user experience and content pretty seriously.
Broken links can be very frustrating. Having broken links on the website translates to disappointing your site visitors. When visitors cannot find what they want, they feel annoyed and do not get a good impression of you.
Fixing Broken Links
Fixing the broken links gives an impression that you will be serious about keeping your site fresh and alive. SEO will surely be highly effective if you are updating your site regularly. It signals the search engine sites that you are maintaining the site.
Broken links can greatly impact your site’s SEO. When all the links on your site are working, it ensures that your site is more accessible on the search engines. However, if you don’t fix these links, your site will get a negative rating for search engine optimization.
Reason for Broken Links
Here are a few common reasons why a link may become broken:
The web page is not present anymore.
The server hosting the target page has stopped working.
Blockage due to content filters or firewalls
23. Unnecessary Redirects
A redirect chain will make the user get multiple redirects between the initially requested URL and the final destination URL.
Consider this, URL A redirects to URL B, which it redirects to URL C. It means it would take a longer time for the final destination URL to load both for visitors and search engine crawlers.
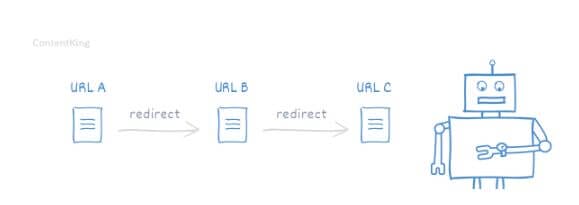 What Leads to Redirect Chains?
What Leads to Redirect Chains?
Redirect chains are an impending problem. Some reasons for these include:
- Oversights: In this case, the redirects are not noticeable to the human eye. It means that while employing a redirect if you are not aware of where you are placing it, you’ll unknowingly create a redirect chain and won’t even notice it.
- Site Migrations: Several times, people forget to update their redirects as website migrations occur. For example, if you’re switching from HTTP to HTTPS or changing the domain name, you might implement more redirects without updating those already present.
How do Redirect Chains Impact SEO?
Redirect Chains can have a bad impact on SEO in various ways.
- Delayed crawling: Typically, Google will follow just up to five redirect hops in a crawl. Following this, Google aborts the task to avoid potentially getting stuck and saving crawl resources and. It will have a potentially negative impact on your crawl budget and lead to indexing problems.
- Lost link equity: Keep in mind that all page authority or link equity will simply pass through a redirect. Every hop in the redirect chain decreases the page authority passed on. Consider this, there are three redirects in a chain, and you are losing nearly 5% of link equity for each redirect. This implies that the target URL gets only 85.7% of the link equity from originally passed on.
- Higher page load time: Redirects lead to higher page load times for users as well as search engines. This further leads to crawl budget loss. Whenever a search engine bot gets returned with a 3xx status code, it will request an additional URL. Otherwise, the search engine bots need to wait, but that means that they get less time to crawl other pages.
How to Clean Up Unnecessary Redirects?
Sites that have been around for a while on the internet gather a cluster of 301 redirects. Most of these redirects offer you authority and are important to keep your traffic stable.
However, you will come across redirects that get stale and stop offering any SEO value they once did. This is because the redirects were built for specific purposes, such as removing old site architecture from Google’s index or removing old vanity URLs.
In such cases, when few redirects stop offering any value to the site, consider cleaning them up as each time the browser looks for the URL, all of those redirects are checked to determine if the requested URL must be sent elsewhere. It can have a serious effect on your load time and result in the users leaving your site. In addition, it can be the reason for redirect chains, as discussed above.
As a marketing specialist you sometimes come across internal links with ‘rel = “nofollow”‘ attribute. It might seem like a good idea to add ‘nofollow to’ unimportant internal links in order to let pagerank flows to the important parts of your page. Unfortunately it is not. We explain why below.
Nofollow is Meant to Prevent Spam
Links on a page pass page rank to other pages. By adding the nofollow attribute tp a link, we ensure that this link no longer passes on a page rank. This nofollow attribute is designed to prevent spam. Webmasters can add the nofollow attribute to links in comments and on forums in order to counteract ‘comment spam’. For example.
<a href=”https://www.example.com” rel=”nofollow”>look at my homepage</a>
Internal Nofollow, A Bad Idea
Internal nofollow links are actually always a bad idea. It is a wrong solution with more adverse consequences than you may have thought. Google’sd Gary Illyes also tells us that internal nofollow should not be used.
For all types of problems there are better solutions than ‘nofollow’
Nofollow does not shape pagerank like you would expect. Nofollow works like a black hole and loses pagerank.
Nofollow indicates that you do not trust a page (enough), which can lead to a higher spam score.
Better Solutions to ‘nofollowing’ Internal Links
There are a number of reasons to use internal nofollow links. You will find the most important ones below with additional tips for better pagerank distribution,
1. The Receiving Page is not Important Enough
This is actually the classic ‘pagerank scultping’ argument.
Pagerank is not otherwise controlled by nofollow but rather evaporates. Moreover, the use of nofollow stops the ‘pagerank flow’. You actually build a dam while you want to move on like that.
If a page is really not important enough, it is best not to link to it.
2. The Receiving Page is of Low Quality
Ai ai ai, you are now trying to hide the fact that you have poor quality pages on your site by masking internal links to those pages. Unfortunately, this is not how it works, Google will detect these pages anyway and will adjust the quality score of your site accordingly. Poor quality pages should be improved or excluded from the index via the robots.txt or meta tags / server headers.
3. The Receiving Page is a ‘Duplicate Content’ Page
Many web stores use / abuse the nofollow attribute at the category level. Product overview pages can be sorted in many ways but the content remains the same. This has duplicate content. Some webmasters have given the links to these pages a nofollow.
Also this is not solved with an internal nofollow but with a canonical where you indicate that the original of this page can be found elsewhere.
25. Site Contains Page Errors
When you click a URL to a site or enter the same in the address bar of any browser, the page will load your device. However, at times, something may go wrong, resulting in an error.
There can be several types of website errors leading to the above situation. Due to this, the URL gets assigned a three-digit HTTP status code.
Typically, you are likely to see error codes in the 400-499 range. These will reflect an error on the user’s side (the web browser). But when you get status codes in the 500-599 range, they indicate a problem on the server-side. Here are some of the commonest errors you encounter for browsing the internet.
Bad Request: Error 400: This is a generic error you get when the server cannot understand the browser’s request. It can occur due to several reasons.
It was not set correctly.
It was corrupted along the way.
Several factors lead to 400 errors.
A bad internet connection.
A caching issue.
A browser malfunction.
Always ensure clearing your cache, check your connection and settings, try different browsers, or simply retry.
Authorization Required: Error 401: The 401 error generally occurs when you access a password-authenticated web page. The user has to obtain the right password through the proper channels.
Forbidden: Error 403: If you try to load a web page that you don’t have permission to access, you will get a 403 error. It means you have entered a URL or clicked on a link going to a page having the set up for access permissions. It means you must use the account with the right type of authorization to access the page. Reaching the website’s home page first, you can go to the desired location. Find out if there is an option for account signup.
Not Found: Error 404: This is one of the commonest errors that says that the server cannot find the page you’re looking at. It might have occurred because you have not entered the correct URL. Therefore, check thoroughly for the spelling, punctuation, and suffixes (.com, .net, .org, etc.) of the domain name and try again.
Method Not Allowed: Error 405: The 405 error is less common and is not as easily defined as the others. When the server can comprehend what the web browser is asking for, it refuses to fulfill the 405 results. The error can also be the result of a faulty redirect due to the website’s code.
Internal Server Error: Error 500: The 500 is similar to the 400 generic code error pointing out unspecified problems. If a server faces an issue to concede to a request due to reasons that do not match other error codes, 500 error results.
Service Unavailable: Error 503: The 503 error signals that the web server cannot process the request due to certain reasons:
The website is undergoing maintenance
Overloaded with requests.
It is best to try again later to override the 503 error.
26. Incorrect Faceted Search
Faceted navigation is the most common issue in eCommerce sites. It gives the website visitors to filter results choosing from facets, a collection of sortings and details, and specific enhancements.
Usually, a large selection of products on any category page can be overwhelming to the visitors. The best way to give them a great UX is to provide them with relevant facets that allow them to narrow down their search results to easily find the ideal product they are looking for. Each filter will append additional parameters to the category page’s URL and generate a few unique page versions. Typically, these filters are used in unlimited combinations, causing a 100-page strong domain to form thousands or millions of indexable URLs.
Here is an example of a page of the shop with T-shirt category Izzi Shop-izzishop.com/products/tshirts/ offers several facets to the user for narrowing down results parameters such as:
Color
Style
Pricing
Brand
Size
Material
Features like cats on the shirt
And more.
The base URL transforms into several different versions on applying all these facets, each of which indicates a uniquely indexable page. See below.
- izzishop.com/produkte/tshirts/?size=14
- izzishop.com/produkte/tshirts/?price=0-20?contains-cats=yes?color=purple
- izzishop.com/produkte/tshirts/?style=baseball?price=20-50?size=12
- izzishop.com/products/tshirts/?size=14
- izzishop.com/products/tshirts/?price=0-20&contains-cats=yes&color=purple
- izzishop.com/products/tshirts/?style=baseball&price=20-50&size=12
Sometimes, it makes perfect sense to index the faceted navigation URLs. However, it is possible only if you have significant demand and will get potential value for enough products to justify the sole existence. It provides a worthwhile search demand for a lucrative long-tail query like “black leather shoe size 42”. It’s vital to ensure a domain has an optimized URL for targeting that search term.
Faceted search is thus an intelligent strategy for SEOs to analyze the performance of this type of URL properly. The strategy will help optimize all the valuable pages while cutting out all the useless weight that lowers the strength of the entire domain.
Impact of Faceted Search on SEO?
Due to the higher usability of a faceted search for your website’s visitors and the product browsers, faceted navigation can lead to several critical issues in the search engines.
John Mueller has created the highest quoted points of 2018 as the “crawl budget is overrated.” It is true for the most part.
Several domains with a keen SEO eye seem to be concerned about pruning the deadweight content for this reason. In the grand scheme of the web, there is not any reason for concern. But, the domain having rogue faceted search URLs will turn hundreds of pages into millions and lead to several unwanted problems, such as:
Duplicate Content
If multiple versions of similar URLs do not have any significant difference in value they offer, they will amount to duplicate pages, but this will be a red flag for Google. It can also lead to a manual penalty that causes dramatic traffic loss or algorithmic penalty, gradually punishing the domains with low value and weak content over time.
This means that even if you have fantastic, high-quality pages that deserve to perform well, the increased share of duplicate URLs surrounding those can be detrimental to your entire website’s performance.
Wasted Crawling Resources
When multiple facets and their combinations create their URLs, your site will face potential harm because the Googlebot and other search engine bots crawl your site and prioritize the content they index. The search engine bot may resort to limiting crawling resources for your domain in its future visits. It will be an issue for sites relying on fresh articles and new inventory, which should be quickly indexed and ranked.

Weakened Internal Link Power
Implementing a logical and strengthened internal linking structure will significantly help in passing and effectively sharing link equity. But the faceted search will weaken this structure because you are diluting the strength to many undeserving URLs, which is not good.
27. Malformed Pagination
URLs with an outgoing anchor link will get malformed href data.
Why Is This Important?
Internal linking is a meaningful way that helps users and search engine crawlers to discover pages on your website. In addition, internal links are an effective method of telling search engines about the importance of the pages on your website.
In malformed links, the link equity does not pass through to the link target. This is because the link is invalid. Moreover, it means that crawlers cannot find the destination URL. Therefore, crawling, indexing, and ranking will get affected.
It will translate into a poor user experience, especially if users cannot navigate the destination page.
What is the Hint Check?
This Hint trigger will onset for all internal URLs containing more outgoing anchor links with malformed href data.
Examples that trigger this Hint
Here are different example links that would trigger the Hint.
See Below.
An anchor with only one /
<a href=”http:/sitebulb.com”>Home</a>
An anchor with an extra
<a href=”http::/sitebulb.com”>Home</a>
An anchor with a mis-spelt protocol
<a href=”htt://sitebulb.com”>Home</a>
How to Resolve the Issue?
It is important to identify the anchors using a malformed href and correct them on a case-by-case basis. If it is a specific common issue, you can fix many pages at once.
28. Search Results Pages Indexed
When a web page is indexed, it means it’s been crawled and analyzed by a web crawler like Googlebot or Bingbot and then added to its database of search results. Your site pages must be indexed before they can populate in a search engine’s results page. A website owner can request for the indexing of a page, allowing it to be discovered naturally by a search engine bot rather than with inbound or internal linking.
The indexed pages are highly useful for various reasons, but the most important one is to read indexed pages. It can appear in organic search results to drive organic traffic to your site. If a search engine indexes your web pages, it will help to determine that your content is relevant and authoritative enough to bring value to users.
Make sure that the indexed page offers a great value so that Google can show it the search results.
Click this link to learn how Matt Cutts explained Google’s stance on this topic in 2007. He referenced the following from Google’s Quality Guidelines page.
Reasons Not to Index Internal Search Pages
There can be several reasons that may seem rather contradictory for eliminating the internal search results from indexation. They were already ranking high in search engine results. But there have been several consequences on how this impacted your site’s performance if you allow the internal site search URLs to get indexed.
Wastage of Crawl Budget and Index Bloat
When there has been a lot of stuff on the internet for search engines to crawl, it is worthwhile to keep things moving. Search engine bots allocate a certain amount of crawl time known as “crawl budget” to each site.
The crawl budget of your site can vary from day to day, but not largely. A crawl budget gets determined by several factors like the size and health of your site.
Optimizing your existing crawl budget will help to ensure that your site achieves the best performance in organic search rankings. It helps to determine the search pages that are highly important for a search engine to crawl and index. Mostly, search engines do not want to waste time on large numbers of pages with thin and duplicate content.
It can lead to index bloat. Index bloat will occur if Google is indexing hundreds or thousands of low-quality pages (not having optimal content) or are not helpful to the site visitors. You will find index bloat when there is a sudden rise in the number of indexed pages present on your site (you can find this looking at the Coverage report in Google Search Console). The several low-quality pages will compromise the overall site quality.
It is important to de-index your internal search result pages allowing the crawl bots to focus on what is truly important for your site. It is important to go for quality content pages that you’ve enhanced and optimized for user readability and conversion.
Impacts User Experience
Make sure that visitors can find what they’re looking for as conveniently as possible. As a user lands on a search results page, in place of finding a page that’s updated to include helpful content, they can be left with questions. Ideally, a user lands on a page that is relevant, helpful, and easy to navigate in place of a page showing a list of products.
This means that an updated internal search works quite nicely to pull up relevant products in the first place. There can be several exceptions to this. Many times, websites have a page they’ve created for a search engine in place of a user landing on to go for a search URL.
29. Ajax Navigations is Not Crawlable
AJAX stands for Asynchronous JavaScript and XML. The technique is used by developers for creating interactive websites employing XML, HTML, CSS, and JavaScript.
AJAX helps the developers to update content as the event gets triggered; you do not have to prompt a user to reload a page. On the other hand, the AJAX website can give a great experience to the users. It can lead to server issues for the different search engines.
AJAX Crawling Scheme
A website implementing the AJAX crawling scheme will offer the search engine crawlers an HTML snapshot for a dynamic page. The search engine gets served an “ugly URL,” and the user gets served with a dynamic “clean URL” of the web page.
For example:
Clean URL in the browser: https://www.ajaxexample.com/#!hello
Ugly URL for crawler: https://www.ajaxexample.com/?_escaped_fragment_=hello
For an overview on how to create HTML snapshots and the AJAX crawling scheme, read the following official guide by Google.
Configuring AJAX crawling in DeepCrawl
For configuring DeepCrawl, make sure that your:
The AJAX website supports the AJAX crawling scheme.
It should get updated for its advanced settings in the DeepCrawl project.
Supporting the AJAX crawling scheme
The team will recommend the following AJAX crawling scheme instructions for implementing them on the AJAX website. Make sure that you take notice of the two ways to indicate a scheme.
AJAX websites:
Having a hashbang (#!) in the URL,
Not having a hashbang (#!) in the URL.
Here are the further details of this setup and how it impacts DeepCrawl.
AJAX websites having hashbang URLs (#!)
DeepCrawl to crawl an AJAX website that has a hashbang in the URL it needs the following requirements:
The AJAX crawling scheme will be indicated on clean URLs using hashbang (#!).
The server of a site is set up to handle requests for ugly URLs.
The ugly URL must have the HTML snapshot of the page.
When these requirements are not met, the DeepCrawl cannot crawl the AJAX website.
AJAX websites without hashbang URLs (#!)
The DeepCrawl of an AJAX website without a hashbang in the URL needs the following requirements:
An AJAX crawling scheme gets indicated on clean URLs employing a meta fragment tag.
The escape_fragment parameter gets appended at the end of clean URLs.
The ugly URL must have the HTML snapshot of the page.
The meta fragment tag and _escape_fragment_ parameter must be included on pages using AJAX. You do not need to add them to every page of a website till all pages start using AJAX to load content.
30. <a href> Tag in Clickable Images
Make sure that you use an image link in HTML, employing the <img> tag and the <a> tag having the href attribute. The <img> tag is required for tagging an image on a web page, while the <a> tag is helpful to add a link. You will get the URL of the image with the src attribute in the image tag. Also, add the height and width.
31. Generic Desktop to Mobile Site Redirection
When you have another mobile eCommerce site, you will have various URLs for mobile and desktop. This means that your search engine optimization requires extra effort.
For example, use the mobile-first index — to rank your desktop and mobile sites, based on signals from your mobile site, it is important to implement the special annotation metadata. Moreover, the redirects are a highly significant factor.
Ecommerce site owners need to understand the growing trend of mobile shopping, which they might believe in giving fewer conversions on smartphones. According to Adobe’s holiday 2018 study, it is worthwhile to note that during November and December 2017, 60 percent of the traffic of e-commerce sites came from mobile shopping, and the remaining 40 percent were sales online.
And mobile shopping has only increased in the past five years. You can very well comprehend why optimizing for mobile search is a priority. The most important thing to understand is that search is the gateway for shoppers. End users will probably use Google it on their phones to find the best gift ideas for making purchases in their busy lives.
Shoppers cannot find your site when they are desperate to make a quick gift decision if your site is not optimized for mobile search.
Responsive sites are highly suitable for mobile search. We presume that they use the meta viewport tag to pass Google’s mobile-friendly test. Follow these steps when the mobile URLs are different.
32. iFrames Usage
iFrames are highly useful tools for helping you to pull the pieces of another website onto yours and put it all together to enhance it. This approach works really well for videos and e-commerce features. Perhaps, it also shows how something works in the form of lines of code from a developer. However, you might wonder if the content from another website will affect your site’s SEO ranking? iFrames play a great role in your SEO strategy. You can use them to your advantage and also grow your website.
What are iFrames?
The iFrame is a shortened version of the “inline frame. It is a segment of HTML syntax which is generally implemented for use as a resource from a website without creating duplicate content. You can use iFrames to embed another website in the code of your website, like a page within a page.
Working of iFrames
Creating an iFrame requires inserting this code:
<iFrame src=“URL of page being embedded”></iFrame>
It’s more beneficial to insert an iFrame code in place of inserting an image. Web developers can easily change the content within an iFrame without altering the code of the whole web page. It is also possible to customize the width and the height of the embedded website. Additionally, one can give it a scroll barthat, distinct from the remaining part of the page having long-form content pieces.
When Should You Use an iFrame?
You can use an iFrame for various reasons:
Embedding videos from YouTube
Running slideshows from SlideShare
Getting maps from Google
Content for advertisements.
An iFrame is also helpful to embed a PDF whereby users don’t require downloading a document.
Additionally, you can use an iFrame:
If you like to share content that is not text-based
If you want to share unique format content
If you’re going to share content that is difficult to replicate on your website platform.
How do iFrames impact SEO Performance?
In the past, Google and other search engines couldn’t crawl iFrame content. So although users could see the iFrames, robots couldn’t. In some cases, once the robots entered the iFrame, they couldn’t get out again, meaning they didn’t index the content on the rest of the website either.
However, today’s web crawlers can usually travel freely between regular website content and iFrames, so no lingering issues remain.
Google recommends providing additional context and links surrounding the insertion of an iFrame to help it better understand the purpose of the iFrame. Many SEO experts also predict that Google bots crawl backlinks to recognize iFrames better. And if that’s the case, these iFrames can add some valuable SEO juice.
How Do iFrames Affect My Site’s SEO Rankings?
Search engines generally consider the content in iFrames to belong to another website. So the best thing you can hope from IFrames is no effect. iFrames may neither help nor hurt your search engine ranking.
That is why it’s most helpful to refrain from using iFrames on main pages that you want to rank on Google or other search engines. Instead, use value-driven and unique content in your high-priority pages and keep iFrames for other pages.
33. Site Constructed in Flash for SEO
Adobe has released new technology for Google and Yahoo allowing search engine crawlers to crawl Flash files. After years of being incompatible, now the set of Flash SEO best practices can help you stay ahead of the competition. SEO for Flash websites is now a reality.
Does Flash SEO Mean Great Rankings for Existing Flash Websites?
No. All-Flash websites that were designed before July 2008 had no reason to be search-engine friendly. Furthermore, because search engines could not index their content, there was no reason to factor searchability into the design process.
Even now, best practices for Flash SEO aren’t completely established. It will take some time to develop this new set of standards, but existing all-Flash websites are notoriously unfriendly to traditional SEO techniques. Simply said, Flash websites and SEO still don’t mesh perfectly.
The existing all-Flash websites are a messy collection of links; some of them are dead-ends with no predetermined navigation structure.
Search engines get repelled from this type of construction. That is why most experts predict that traditional SEO websites will stay on the top of search engine results pages even if the SEO for Flash websites becomes prevalent.
Flash SEO Mean Prettier Websites
Flash SEO is still in its infancy, and it is bringing forth websites with better aesthetics. As flash SEO continues to grow, you can look forward to prettier websites. Unfortunately, the Flash SEO problem has hindered several talented designers that wanted to create several beautiful pages with Flash. The search engine impediments will help deter them from Fash site’s SEO impediments. SEO and Flash websites couldn’t go together.
A completely all-Flash website can be a risky move if the Flash SEO standards get established. However, Flash gives the ability to follow links making Flash technology highly useful. But with progress in the development of Flash, the optimization of the Flash will become more prevalent. So as Flash develops more, SEO for Flash-based websites will become more common.
How Flash SEO Enhance Search Engine Results for your Users?
Early researchers have found several troubling problems. “Flash bombing” had been a big problem. This is because Google’s robots index the various hidden and non-hidden links in a Flash video. As a result, deviant developers may hide hundreds of invisible links. In addition, search engines will determine rankings relying on making a decision based on links. Thus, there is an excellent chance of spamming.
In the late nineties, such types of linkig problems were highly irritating for the search engines. As a result, the SERPs got filled with spam due to unethical linking practices. Only after a few years was Google able to find a solution to the problem.
As Google finds a problem with the solution to follow Flash links, it will open up opportunities for spammers that do not want to go for legitimate methods on performing the SEO for Flash websites.
All in all, Flash SEO is not entirely feasible till this issue gets suitably addressed.
The impact of Flash SEO on the future of search engine rankings is yet to be seen. The best internet Marketing agencies like SECI have already started experimenting.
34. Excessive Pop-up Windows
There are several kinds of pop-ups that website owners can use. When you think of making things highly creative, you tend to load it with pop-ups. But, the excess use of the pop-ups blocks the view of the page carrying the main content and the website’s message.
Moreover, full-screen pop-ups block the full view of a page. Thus, it is possible to see the lightbox pop-ups blocking a portion of the page. Generally, one will set a pop-up to trigger a short delay in the user scrolling to a particular part of the page or use the exit-intent pop-ups starting as a user’s mouse hovers on the top of the browser window.
Impact of pop-ups and interstitials on the SEO
Google’s search algorithm has a specific check for pop-ups and interstitials on mobile. If the pop-ups on mobile get detected and are found to be obtrusive, then your pages may rank lower.
“Pages showing intrusive interstitials provide a poorer experience to users than other pages where content is immediately accessible. This can be problematic on mobile devices where screens are often smaller. To improve the mobile search experience, after January 10, 2017, pages where content is not easily accessible to a user on the transition from the mobile search results may not rank as highly.” – Webmaster Central Blog.
The complete SEO impact of using pop-ups and interstitials can be relatively more significant than just a direct search penalty. If access to your content is blocked due to the interstitial, it will lead to higher bounce rates and less user time spent on the websites. There will be fewer page visits, which will also mean you get fewer links to your content. This means that the broader SEO penalty will be huge.
High quality and relevant links are a significant ranking factor in Google’s search algorithm. Unthoughtful pop-ups will genuinely reduce your chances of getting a good deal of organic traffic and visitors that want to engage with your content. Also, note that Google wants to rank pages offering valuable information to people about their area of interest. High bounce rates and low time spent on the page suggest that your content does not belong at the top search results.
But there are also benefits of using SERPs.
The Pros of Using Pop-Ups on Your Website
Casting Google updates aside, you get various positives for using pop-ups for your desktop traffic:
Pop-ups are great for conversions – There are several case studies indicating that pop-ups increasing lead counts.
Pop-ups grab the users’ attention – The pop-ups hijacking the entire screen, not for no reason. Pop-ups get a great deal of attention.
They focus on conveying one message –There are so many types of messages on your site. But pop-ups are a space where you focus on a single call to action (CTA).
Huge ROI potential – Pop-ups do not cost very little but generate a great ROI.
Pop-ups are less intrusive nowadays – The newer variations of the pop-ups are much better and less intrusive than the traditional ones and do not interfere with user experience.
But pop-ups and interstitials are meant for conversions of the user. This is how you can be in a bit of a dilemma. If conversions are a priority with you, then pop-ups are something you want. However, if you are focused on higher rankings and giving the best user experience, pop-ups take a backseat. The decision will be yours to take.
The Cons of Using Pop-Ups on Your Website
There are several reasons why you should not use pop-ups and interstitials. And they existed in a big way even before Google made changes in its algorithm.
Pop-ups are very annoying – Especially the full-screen intrusions and on mobile devices.
Block content – Pop-ups load last and cover the information the user was going through with interest. So, they negatively impact user experts.
Users are forced to take action – Though pop-ups may give great conversions, they only exaggerate the website owner’s intrusion and lead to more or less forcible conversions.
Increase the bounce rate – The most typical action users take is leaving your site.
Lead to loss of potential leads – On one side, you may be getting conversions from pop-ups. But on the flip side, pop-ups will be interrupting the user sessions.
Potentially damaging to brand reputation – The pop-ups have a spammy nature. This is why they do not actually boost the confidence of the consumers.
Ultimately, it boils down to what value pop-ups bring to your marketing strategy. If you are generating solid leads using the pop-ups, then they can be worth the compromises.
35. Relevant Content Contained within PDF or Other Formats
Several search engines, including Google, can quickly locate and read PDF files present on your website. But these documents generally lack basic information allowing search engines to find out what the content is about. This ultimately has an impact on your position in the search results. In an audit for technical SEO, this is an important parameter.
Before creating content for a bunch of PDFs-
It is worthwhile to note that certain types of content are remarkable for their use in PDF format. But, the most important content must be placed at the top of the other regular HTML web pages.
Visitors can easily engage and interact with your website on the standard regular web pages than with PDF documents. It is pretty easy to place a call to action (CTA) on an HTML webpage, for example, CTA for filling out a form.
The Importance of Title and Subject
The title of a PDF file is a crucial factor that affects search results. Google may sometimes have to consider thousands or even millions of pages to select from while matching a search query to a website page. It is pretty unlikely that the PDF will appear in the top five results except if the PDF content is what users are looking for.
Continually update the file properties for a document before creating its PDF:
Word for Windows PC: File > Info
Word for Mac: File > Properties, Summary tab
The title of your document is a vital factor in making it rank in search results. It is the subject text that will generally appear in Google’s search results. And it can influence a searcher to click.
Google search results can include the content from any part of a document. But, notice that the text from the PDF Title, URL, and Subject will get included in the search results below.
36. Checking Entries with User-Action-Required
Back in years, Google heavily relied on two aspects to determine rankings in their monthly refreshes (referred to as Google Dance). These were:
Plain text data
Backlinks
Google search has evolved a lot from those days, and now it stands against us as a sophisticated product employing a plethora of algorithms wired to promote content that appears in results addressing the user’s needs.
Actually, a large part of SEO is a numbers game. Why> Well, here lies the answer.
Don’t all the SEOs look for the improvement of the following parameters in our SEO?
Organic traffic levels.
Rankings.
Onsite conversions.
Search volumes.
Numbers all!
These are the metrics we want to measure across competitor websites via third-party tools).
Your clients want their website to rank higher and get an improvement in organic traffic, leads, and sales.
The whole exercise of choosing and finding the target keywords is about catching the audience’s attention. No wonder finding the search keywords with the highest search volumes is important. That said, it is necessary to consider the intent behind the search volume.
37. Buried Deep / Island Pages
If a page is buried so deep that it takes a number of clicks to find it, it is an island page. The parameter to determine this attribute is known as Page depth. It is the number of clicks it takes to reach a page from the Home page using the shortest path.
Your site’s Home Page is at 0 Depth. It is considered the ground floor of your website. The About Page displayed on the tab on the Home Page is at Depth 1 or the first floor. A page that has its link on the About Page is at Depth 2, meaning that it requires two clicks from the homepage for a user to access it with the shortest possible path. Understand Page Depth with the following diagram.
The Home page at Depth 0.
The main categories of Shoes, Accessories, Clothing, and Sale (on home page) are all at Depth 1. They are just a click away from the home page.
For subcategories, customers need to go deeper at Depth 2 to get information on men’s clothing or children’s shoes.
If you reach Depth 3, you can also find other pages like men’s pants or children’s sneakers and more.
Sometimes, too high page depth can be a subjective accusation. For example, for a website with 20 pages, “ too deep” will have a different perspective from a site with 20 million pages.
The measure of excessive depth can also be based on the type of content present on the page-in-question. For example, crucial, strategic content should have less page depth than anything extra fluff and not so important for the customers or search engines?
However, Page Depth of important content is a critical metric when it comes to the SEO perspective. A visitor or the crawler should reach a strategic content in less than or 5 clicks (page depth 5). If the page depth is higher than 10, Google’s crawler and visitors will abandon their quest to access such a page. Most impatient customers are likely to bounce off the site if they cannot easily access or find what they’re seeking. And the bots consider your deeper pages not worth the limited crawl budget.
How to Avoid ‘too deep’ Strategic Content?
If your website has many deep pages, there may be several factors to blame. An important SEO problem here is content inaccessibility. You must know the origin of the issue within the site structure.
Ways to prevent excessive page depth
Keep a check on pagination problems
Pagination can give rise to greater page depth due to several factors, including:
Less number of items per page
Very long lists
Ability to navigate just a few pages at a time.
Try to create shorter lists or offer more items per page. It will help you to cut down on the number of pages. It will also help stop robots from reaching and crawling low-quality and unhelpful pages, including very long lists, as you update the robots.txt file to discourage crawlers.
Limit Navigation Filters
If there are too many filters in your navigation, especially those that create new pages, it can make you run into depth problems rather too quickly. Make sure you limit the number of filters that are crawlable by robots. The best practice is limiting to a single or two filters at the most. It means that you must do away with useless filter combinations that aren’t leading to deep pages driving organic traffic.
Move Your URL Tracking Parameters
Make sure that you are tracking parameters (like ‘?source=thispage’), which can create many indefinite URLs allowing tracking of the on-site parameters. The source pages help to create duplicates for important content. Moving the tracking information behind a # at the URL’s end will help you change the destination and wouldn’t duplicate important pages.
Correct Malformed URLs
Keep in mind that malformed URLs are a silent enemy of your website. It can result in a 404 Not Found HTTP status code, which is bad for your UX and SEO. Malformed URLs can also return the OK 200 HTTP status code. You can replace all the:
Malformed links
Missing human-readable elements
Repeated elements
Have correct links on the website.
Put an end to perpetual links.
Several templates feature links present on every page. It can be the next day or next month present on the calendar – which creates an infinite number of pages, which is so bad for your SEO. It is necessary to create a full stop to perpetual ‘next’ links. Do this by adding an ‘end’ value that prevents creating an infinite number of new pages.
How do You Know if Your Content is Too Deep?
There’s the trick to explore if the content is too deep. These issues are all serious. But, it is important to know if these are happening on your site. You cannot just guess based on things you know about your website, but you will need conclusive data that you can be sure of.
Always run a thorough analysis of your website from top to bottom, inside and out—an exhaustive scan of various parts of the site.
You need to get access to a complete picture of the page and every URL. Check every nook and dark corner of your website and also the surface.
As you proceed towards the distribution section of your analysis report, it will help you to know which pages are at Depth 1, 2, 3‚ and the ones past the cut-off of Depth 5? You will also get an insight into the content which is buried down at those depths.
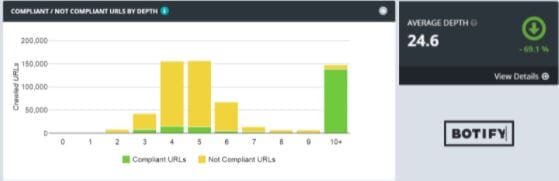
This feature helps you to discover how your pages will be distributed across your website. Explore more to understand what content is present at those depths as you click through to find the sections in your site that are located far too deep for crawlers to them. Depending on the causes mentioned, create a to-do list of fixes.
You need a deep understanding of your website’s structure and location where the strategic content lies to get ready to work on your next step.
38. Search Engine Incompatibility
A browser engine is the heart of the browser. As you hit the URL of the web address, it presents to you the content of a website. It carries this function with an understanding of the CSS, JavaScript, and HTML present on your web page. It might sound very simple, but it is not really. It is because the browser engines are designed uniquely for every browser. That is why each browser engine has its unique way of the Web’s interpretation, which leads to cross-browser compatibility issues.
JavaScript & Rendering Engine- The History of Becoming
Let’s go back to when the InternetInternet came into the picture, and only a few people had access to it. Those were the times when the user and the developer were very few in number. The websites that developed were static and simple, very much unlike what it is today. It is important to understand the dynamic functionality of a website and how it can be done naturally. Javascript was not born and was not even needed at that time. While Netscape and Microsoft started competing with each other, it led to the invention of the browser engines for the popularity of their browsers.
Netscape developers decided to implement few functionalities to compete with Microsoft, taking into account the user experience, and they finalized Scheme language to be their language category for moving ahead. It is important to modify the coding experience to allow flexibility in the website world.
We are talking of the time when the InternetInternet just got started. As Jack Ma introduced the InternetInternet to his friends, it took 20 minutes to load a page. As Netscape collaborated with Sun Microsystem to use Java, the more static language, along with an idea of the scheme language. It gave rise to Javascript.
Javascript then opened an endless number of opportunities for web developers to use on their website because it was more than just putting tags or styling on the Web. It put down a huge responsibility on the browser engine as it was not just converting the tags to visual elements. There were also a lot of backends too. Previously, the browser engine’s work was divided into new engines:
Rendering engine
JavaScript engine.
The Javascript, browser engines, and websites all were evolving at a high rate. They have two components that are dependent on each other and require them to work in tandem. The browser collapses to render a website even if one of the engines falls.
39. Technical Audit of Cross-Browser Incompatibility
There has undoubtedly been such a surge in the use of the internet in the past twenty years. From 2.4 Million websites in 1998, there are nearly 1.8 billion after two decades.
A whopping increase of 74900%.
And there has been an equivalent rise in the internet users
1998: 147 million
2018: 4,157 million.
An increase of 2727%.
The latest significant trend in internet usage is the number of mobile users.
1998: 318 million
2018: 7740 million.
A direct increase of 2333%.
The Internet stores all kinds of information with a vast oceanic and galactic volume of content; multiple lifetimes would fall short if you want to go through it all.
From Mexican Taco recipes to rocket science like technical information for physics, metaphysics, healthcare, everything is there.
Imagine the large populace viewing this content from their ten thousand different types of web-enabled devices.
That’s why it’s a cause of concern.
If there are more users, more devices, platforms, and browsers, it gives you more ways to view your website. The important concern here is for the users that are browsing the website on so many distinct devices. You should be able to see your website the way you want them to see
The growth in the web also resulted in multiple different types of technologies to build this web ecosystem, and with significant numbers of various tools, like web browsers, to access and interact with this content. However, all technologies are not mutually compatible with each other. The web developer always has to ensure that their website gets compatible with the different existing technologies. So, there is a need for browser compatibility testing.
It is not hard to understand that if users face this problem, they will, without a doubt, leave your site and get a wrong impression. That’s why cross-browser compatibility is an essential thing.
More on the Need for Cross-Browser Testing
Typically, most developers tend to have a favorite browser, resulting in “Browser Bias.” Your favorite browser is the latest version of chrome or firefox. Isn’t it? Developers will develop and debug the whole product on that browser. But, the important thing one needs to keep in mind is the users can be anyone using any browser. Therefore, it is not advisable to direct our function based on a browser bias. Otherwise, it will affect our product. Be open to using browsers that you ignored respectfully because you never know if it is the favorite browser to the target users.
The latest 2-3 versions of chrome may have the highest coverage, but it cannot be 100% if you cannot develop a product for the rest of the users for it to be well designed.
Take a bite: Recent Global stats indicate that Chrome and Safari are among the top 3 browsers in 2020. But keep in mind that it can be misleading as different people use different browsers in other areas.
40. Bing SEO Technical Audit Checklist
If Bing crawls and indexes pages on the Internet, it needs to decide about the pages that are most likely to resonate with searchers. All pages do not get selected due to the virtually infinite size of the Web. Due to this, your pages may currently not be present in the Bing index. Read further to understand how you can verify if a page from your site is present in the index. Also, ascertain the common reasons why a page has not made it into the index and what are few tips for finding out what you can do to improve your chances of indexing.
There are several reasons why your website is not present in the Bing index. First, you must verify if this is really the case with your website. To this end, raise a query for the specific URL of your website, using the URL: search operator and then your site URL. The following example shows that the URL is in the index, as it gets returned as an outcome.
There may be several reasons why your site or page is not getting indexed. Moreover, it can be due to a combination of the following:
New site Bing has not discovered and crawled as yet: Bing takes time to find links and crawl through a new website. Yes! You may submit sitemaps or submit pages directly to Bing with your Webmaster account while following guidelines mentioned in Submit URLs to Bing; Bing needs to crawl and assess the website for it to get indexed.
Bing is finding issues while crawling your site: If Bing is finding many issues on your website consistently in its attempt to crawl your website, It may not select the website to be indexed. Moreover, the live URL section present in the URL Inspection tool helps to see if the main crawler, Bingbot, can crawl your homepage and other pages.
No links point to your website: One of the common problems in the new websites is a lack of links pointing to it from various places on the web. If you want to rank well on Bing, you need links to your website, just as in Google. Links help Bing, and other search engines discover your content. It’s no secret now that links are like votes. So, links also tell Bing how popular your site is. While building links for a search engine, remember, you need to go for quality and authoritative websites pointing at your website rather than getting hundreds of new links from random spammy sources in a jiffy. Bing will need at least one link pointing to your website so that it can find and index your site. It is obvious that the more the number of quality links to your site, the better. Creating compelling link-worthy content is the best way to get quality links pointing to your site.
The robots.txt file may prevent Bing from crawling your site: Incorrect settings of your robots.txt file will inadvertently push away Bingbot and tell them not to crawl your website. It could potentially keep your site hidden and not get indexed. Check how you can create a Robots.txt File and learn more about how you can properly set up the basic robots.txt file.
Check if you have a <meta name=”robots” content=”NOINDEX”> on your pages: Bing will not add your pages to the index when your pages contain <meta name=”robots” content=”NOINDEX”> in the page’s source code,
Do you have blocked URLs in your Bing Webmaster Tools? If Webmasters knowingly or unknowingly block the active Webmaster account with Bing, Bing will not index the page. You can find such a blocked URL using the results of the Block URLs tool. Always check your account to ensure the URLs you want to get indexed are not blocked here.
Your site is not meeting the quality threshold specified by Bing: Like Google, Bing has an affinity to unique and high-quality content. You must create quality content and make sure your site does not have duplicate content issues. Check and fix excess redirect errors. The page should be accessible to the users quickly and offer them depth into what they are looking for. Bing will disfavor the sites with a record of prolonged poor performance in favor of quality websites.
Has Malware Been Detected on Your Website?
If Bing detects Malware on your site that is a potential threat to the users, it will either remove your website from the index completely, or it will label it Malware detected to alert its users. Bing may also assess a penalty for the website and remove it from the index. Bing will communicate directly with webmasters about finding Malware on their website. Follow the Bing Webmaster Guidelines to correct the issue if your website has been hit by Malware.
41. Shared IP Address Issues
The entire point of maintaining a website is to draw in visitors, views, clicks, whatever you’d like to call the people who view your pages.
Dedicated hosting is all the more important if you have an e-commerce website. Otherwise, dedicated hosting may not bring any extra value to you than shared hosting.
SSL certificates provide higher security in e-commerce transactions. Google has stated publicly that SSL certificates increase SEO.
It also means that these certificates are available only to websites having a dedicated IP address.
Dedicated IP addresses will help websites to load faster. A lesser server data translates to a lesser time returning browser requests.
Apart from this, if you may choose reputable hosting companies and you don’t have an e-commerce website, shared hosting would not be detrimental to your SEO.
42. Site Hosted in A Country Different from Target Audience
It can be a hard choice to pick up the best web host. It can be overwhelming to choose from the thousands of web hosting offering the same product at more or less similar prices. Finding the best web host will be an important choice, especially when it comes to the location of the server.
Website Speeds and Loading Times
High Page load time is the main reason why users abandon bounce back from a website, because an average user does not have enough patience to wait for a slow-loading website. According to recent research, 53% of mobile users will leave a website that takes greater than three seconds to render in its entirety. Moreover, Google also takes into account the page loading speed while ranking pages. When your webs page takes more than standard time to load, Google will drop your rankings. Additionally, you may also get server-related issues. If your website is hosting far from your target users, it will impact your web page load time significantly.
If your website is targeting users just from one country, it is best to locate the server in that particular country. But, if your website is targeting customers from various countries and from around the world, it will be a different story.
Results for Google
Google experimented across 162 different countries where it had a country-specific website. They found that 136 out of 162 countries had faster country-specific websites. It was found that country-specific websites witnessed an increase of about 12% in their performance.
43. Robots.txt File is Missing
Robots.txt comprises a text file that webmasters use to instruct search engine robots on how to crawl pages on their websites. The robots.txt file is a part of the robots exclusion protocol (REP). They have a group of web standards regulating the way robots will crawl and assess the web to index content that serves user intent. The REP also lists directives on how search engines list content for the follow or no-follow links.
Meta robots
Page-, subdirectory-, or site-wide instructions.
In most cases, robots.txt files indicate if certain user agents like web-crawling software can or cannot crawl the different parts of a website. The crawl instructions specifications include the “allowing” or “disallowing” the behavior of specific or all the user agents.
Basic format
User-agent: [user-agent name]Disallow: [URL string not to be crawled]
These two lines together equate to a complete robots.txt file. A single robot file may have multiple lines mentioning different user agents and their directives (disallows, allows, crawl-delays, etc.).
Each set of user-agent directive will appear like a discrete set that gets separated by a line break:
In the case of robots.txt file having multiple user-agent directives, an allow or disallow rule will just apply to the useragent(s) names mentioned in the particular line break-separated set. When a file contains a rule applying to multiple user-agents, the crawler pays attention to ( the directives in) the highly specific group of instructions.
Here’s an example:

In the above illustration, you can find that msnbot, discobot, and Slurp are all specifically called out. These user-agents will just pay attention to the directives in their respective sections of the robots.txt file. Other user-agents follow the directions in their user-agent group.
Here are a few examples of robots.txt in action for a www.abc.com site.
Robots.txt file URL: www.example.com/robots.txt
Blocking all web crawlers from all content
User-agent: * Disallow: /
This syntax in a robots.txt file instructs all web crawlers to refrain from crawling any pages on www.site.com, including the homepage.
Allowing the web crawlers to access all content.
User-agent: * Disallow:
This robots.txt file syntax tells the web crawlers to crawl all pages on www.example.com, like the homepage.
Blocking certain web crawler from specific folders
User-agent: Googlebot Disallow: /example-subfolder/
This robots.txt file syntax only tells Google’s crawler (with user-agent name Googlebot) to not crawl any pages containing the URL string www.example.com/example-subfolder/.
Blocking a certain web crawler from a specific web pages
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
This robots.txt file syntax instructs only Bing’s crawler ( with user-agent name Bing) to not crawl the mentioned page url. at www.example.com/example-subfolder/blocked-page.html.
https://moz.com/learn/seo/robotstxt
44. Robots.txt File is Blocking Valuable Content
#1. Block Specific Web Pages
Robots.txt is to block web crawlers’ access to specific web pages of your site. However, you should definitely follow the seoClarity recommendations.
seoClarity Tip: When you want to block specific pages from crawling or indexing, it is advisable to add a “no-index” directive to the page level. Add this directive globally using the X-Robots-Tag with HTTP headers being the ideal solution. If you require specific pages, add the “noindex” on your page level. Google provides several methods to do this.
A disallow line in your robots.txt file may present a security risk because it identifies the location of your internal and private content.
How to prevent this from becoming an issue?: If you use a server-side authentication for blocking your access to private content. It is specifically required for your personal identifiable information (PII).
45. Robots.txt File is Missing XML Sitemap
When a sitemap has an XML file containing a list of the metadata (metadata being information that relates to each URL). and various web pages on your site, a robots.txt file works, in the same way, using a sitemap. In other words, the sitemap allows search engines to crawl through the index of the various web pages on your site present in a single location.
How to create a robots.txt file with sitemap location
You can create a robots.txt file with your sitemap location in three steps.
Step 1: Locate the sitemap URL
If a developer has already created a sitemap for your website, it is likely to be present at http://www.example.com/sitemap.xml. Replace ‘example’ with your domain name.
To access your sitemap present at this location, type the URL into a browser, and you will be able to find the sitemap. If it is not present, you will get a 404 error meaning the sitemap does not exist in that location.
Another more straightforward way to find your sitemap is via Google’s search operators. Type site:example.com filetype: XML in Google’s search bar. Google will find it for you.
If you can’t find your sitemap in either of the two ways, it indicates that the sitemap does not exist. Generate a sitemap yourself or get a developer to create one for you.
Step 2: Locate your robots.txt file
Like your sitemap, you can inspect if the robots.txt file has been created on your website earlier. Just type http://www.example.com/robots.txt (replace ‘example’ with your domain name.).
If you don’t have a robots.txt file, then you will need to create one and ensure that it has been added to the top-level directory (root) of your web server.
Just create a .txt file to include the following text:
User-agent: *
Disallow:
The mentioned text allows the various bots to crawl through all your content.
Step 3: Add sitemap location to robots.txt file
In the end, you must also add your sitemap location to your robots.txt file.
For this, you must edit your robots.txt file and add the directive for the URL of your sitemap in this way:
Sitemap: http://www.example.com/sitemap.xml
Now, the robots file will look somewhat like this:
Sitemap: http://www.example.com/sitemap.xml
User-agent: *
Disallow:
46. Checking if Robots.txt is Blocking XML Sitemap URLs
Using the “disallow” rule in the robots.txt file can help the different user agents in several ways. Learn about the different ways to help you in formatting the several combinations in blocks.
Keep in mind that the directives in the robots.txt file are just the instructions. It means that the malicious crawlers ignore the robots.txt file and help you to crawl the various parts of your site that the public sees. However, ‘disallowing’ cannot replace strong security measures.
Multiple User-Agent Blocks
List multiple user agents in front of the set of rules; for example, you can use the following disallow rules that apply to the robots of both Google and Bing, in the block of rules as follows:
User-agent: googlebot
User-agent: bing
Disallow: /a
Spacing in the Blocks of Directives
Typically, Google ignores the spaces present between the blocks and directives. Here are two examples.
First example.
You can go for the second rule, though there is a space separating the two different parts of the rule:
[code]
User-agent: *
Disallow: /disallowed/ Disallow: /test1/robots_excluded_blank_line
[/code]
Second example.
Here, Googlebot-mobile follows the same rules like the Bingbot:
[code]
User-agent: googlebot-mobile User-agent: bing
Disallow: /test1/deepcrawl_excluded
[/code]
Separating the Combined Blocks
You will find that multiple blocks having the same user agent get combined. In the following example, the bottom and top blocks get combined, and the rule disallows Googlebot to crawl “/b” and “/a.”
User-agent: googlebot
Disallow: /b User-agent: bing
Disallow: /a User-agent: googlebot
Disallow: /a
47. Robots Meta Tag
The robots’ meta tags or the robots’ meta directives are also known as pieces of code providing crawlers the instructions on how to crawl or index web page content. The robots.txt file directives give the bots with suggestions on how they can crawl the website’s pages. Robots’ meta directives offer more specific and firm instructions for crawling and indexing a page’s content.
The Two Types of Robots Meta Directives: The meta directives are a part of the HTML page (like the meta robots tag), and there are few that the web server will send them as HTTP headers (example, x-robots-tag). These include the same parameters (of crawling or indexing instructions given by a meta tag, for example, the “noindex” and “nofollow” in the example mentioned). They can be employed with both meta robots and the x-robots-tag. But, the difference lies in how the parameters get communicated to crawlers.
Crawlers receive instructions on crawling and indexing information on a specific webpage from the meta directives. As the bots discover the directives, strong suggestion parameters get established for guiding the crawler’s indexation behavior. When it comes to robots.txt files, crawlers do not have to follow the meta directives you’ve specified. It is a safe way to keep away malicious web robots from your directives.
Here are some parameters search engine crawlers use to determine when they get used in robots’ meta directives. These parameters are not case-sensitive. However, note that there are chances that some search engines follow a subset of these parameters and may treat few directives distinctly.
SEO Best Practices with Robots Meta Directives
If a URL gets crawled, all meta directives (robots and other things) get discovered. In other words, if a robots.txt file disallows the URL from crawling, the meta directive on the page (present in either the HTML or the HTTP header) won’t be considered and will be effectively ignored.
In general, while using the meta robots tag with parameters of “noindex, follow” must get employed to restrict crawling and indexing in place of using robots.txt file disallows.
The chances are that the malicious crawlers will completely ignore meta directives. Thus, this protocol does not provide for a good security mechanism. To secure your private information from public search, choose an approach like password protection that prevents visitors from viewing confidential pages.
Never use both meta robots and the x-robots-tag on the same page – as it is a redundant exercise.
48. Google Search Console Not Set Up
Google Search Console is important for businesses that want to get greater website traffic from search engines. If you are unsure of what Google Search Console is and why you require using it. Read the Google Search Console blog first.
How to Set up Google Search Console
Set up Google Analytics first, then add Google Search Console, which is very easy.
Go to Google Search Console.
Now, all you need is to log in. In Google Analytics, log in using the credentials of your Analytics account. Alternatively, log in using a Google account. Keep in mind that you need a Google account to continue.
As you log in, click on the “Add A Property” button at the top of the page.
Enter your website’s URL, and click continue.
Then, you have to verify being a website owner in these ways:
Upload an HTML file if you have access to your website’s root.
1. Those who manage their hosting must verify through a hosting provider.
2. Verify via Google Tags employing the Google Tag Manager.
3. Use the Google Analytics Tracking ID to verify your ownership in an easy and quick manner.
4. If you already have installed the Google Analytics Tracking ID, then click on the Verify button to set up Google Search Console!
49. GSC Targets Correct Country
Employ the International Targeting report for monitoring your hreflang errors. It allows you to choose a country that you must prioritize for your search results. The report has these two major sections:
The Language section: It checks your site’s usage and errors of hreflang tags.
The Country section: It helps to set a site-wide country target for your whole site if required.
Language tab
The International Targeting page’s Language section shows the following hreflang errors present on your site. It can show up to 1,000 errors.
|
Error |
Description |
| No return tags | This hreflang tag does not have a matching tag on the target page. The table lists aggregates of missing return tags with the locale and implementation and locale for the following:
|
| Unknown language code | The table displays the locale followed by unknown language code for unknown language or optional country) codes you may have indicated on your site. Just like the no return tag error, you will dig more to find total counts of unknown language codes and the URL-level details for a specific locale. |
50. Site Currently has a Manual Penalty
Type #1: SPAM actions and Manual penalties
Most of Google’s penalties get imposed in an automated manner. But, specific penalties get assessed by the human reviewers of the search engine.
You’ll get an alert in your Google Search Console dashboard in the case of a manual penalty hitting your site. Plus, you get an email alert.
51. Mixed Content: HTTP in HTTPS Site
Users get safeguarded from the man-in-the-middle attacks on pages served over HTTPS. The connection with the webserver gets encrypted with TLS. The HTTPS page will include the content fetched with a cleartext HTTP. It can be addressed as a mixed content page. Such pages are just partially encrypted. It means the unencrypted content is accessible to man-in-the-middle attackers and sniffers. Overall, the pages are deemed to be unsafe.
The difference between passive or display mixed content and active mixed content
Passive/Display Mixed Content: When the unencrypted HTTP content gets restricted to encapsulated elements on the site, it cannot interact with the remainder of the page, for instance, if the unencrypted content on the page comprises videos and images, the attacker can block or replace an image loaded over HTTP but won’t be able to modify the rest of the page which can be text.
Active Mixed Content: The elements or dependencies (like JavaScript files and API requests) can interact with and change the entire webpage if it is served over HTTP.
Active mixed content is a more severe threat than passive/display mixed content. If left uncompromised, it allows the attacker:
To take control of the entire webpage.
Collect user sensitive information like login credentials.
Serve spoofed pages to the users.
Redirect the user to an attacker’s site.
The modern web browsers offer several warnings in their developer console with regards to mixed content. They also block hazardous types of diverse range. Every browser has its fixed set of rules, but in general, the active mixed content is quite likely to be blocked.
The passive/display mixed content is associated with a lesser threat; it offers the attackers an opportunity for attackers with compromised privacy and also helps to track user activity. Apart from this, a lot of browsers provide certain forms of passive mixed content while giving the users mixed content warnings in their developer console. Several users are not aware that they are being exposed to diverse content.
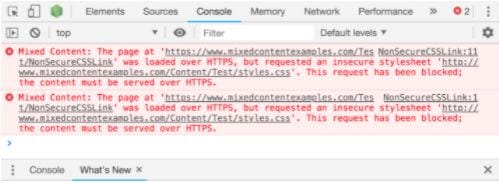
Users with out-of-date web browsers are highly vulnerable, and these browsers will not block the mixed content.
52. User Interaction Analytics
Organic Click-Through Rate
Google keeps track of which pages within the SERP get more clicks. Therefore, the pages with higher click-through rates are more valuable. Over time, higher click-through rates will result in a better rank for that keyword, as Google will see your website as a good resource for that particular search term.
Direct Traffic
Typically, Google uses chrome to gather information about website direct traffic. What does Google track?
Websites visits
Frequency of their visits. A website that incurs more significant traffic from unique users will be considered a higher quality website. It means that the volume of traffic a website gets impacts its rank. Therefore, websites with more increased traffic get a higher rank.
Pogo Sticking
“Pogosticking” is a particular kind of bounce on search engines. Understand like this;
Suppose users search do not answer their query on the first set of their choice; they bounce to the search results and hop to the other websites to find the answer. This is known as pogo-sticking. If Google finds that users are pogo-sticking from your site, Google will think that your site is not offering answers to their queries. Thus, it will lower your site’s reliability for Google for serving user queries. Ultimately, pogo-sticking leads to a lower overall rank.
Page Comments
If your site has pages that allow people users to comment, the rule of thumb is the greater the number of comments, the better it is. A lot of comments mean visitors find your content engaging. Google emphasizes showcasing interesting and engaging content. So, pages with a large number of comments get a better ranking on Google.
53. No Breadcrumb Schema in Google Search Console
If there is a missing field “id” in Breadcrumbs on Google Search Console, it can lead to navigation issues. This may occur due to the latest feature on Google Search Console. It requires thorough analysis and fixing.
54. Excessive Inline CSS
Every technical SEO audit guide will include inlining as an important parameter for determining site performance. Inlining involves the integration of a portion of code directly in the place where it will get used. It eliminates the requirement for a computer to carry out a functional calling and other types of lookup. This provides for a faster code.
The inlining terminology is derived from a C programming language—the concept and the name help to explore web development. CSS offers you a performance gain derived from the inlining styles. This should then reach directly to the HTML document. There is a great need for the browser to carry out a network request before getting the render-blocking styles.
What Type of Inlining Should You Avoid?
To conduct any research on the inlining CSS, you will be finding various suggestions in the inline styles like this:
<p style=”font-size: 20px; font-weight: bold;”>Some text</p>
It can be called true inlining because there will not be a need to get a network request for fetching the external style sheet or why the browser needs to apply a CSS class name to its element. Do not inline CSS like this because it leads to certain performance losses because the runtime responsiveness will be the unit of measure.
Few reasons why you should majorly always avoid inlining CSS like this:
Render-Blocking Load Time
It will take you back to the CSS concept, which is a render-blocking resource. According to the network requests, it is generally present that gives you the amount of time a browser requires to parse through to comprehend all the CSS.
For example, suppose you want to avoid loading the external CSS stylesheet and also the inline of each element in the DOM individually. In that case, you will get several duplicated styles, either atomic CSS class names or the common class names for the correct type of element. The benchmark of developers indicates the inline-styling for every HTML element will significantly affect the time to first contentful paint.
Duplication of Styles
You can save yourself a great deal of time if each element is not individually styled while inlining CSS. It will save you a great deal of effort as well. Several ways help you define styles as being a reusable object and spread these styles into every element. Unfortunately, each component will be individually styled at a mundane point and will make things harder for a future refactor.
Specificity of Styles
When the duplication of styles does not provide enough of a warning to “turn back now,” then it will be suitable to understand that the inline styles having a high specificity may simply get overwritten with the use of ! necessary declaration.
Overall, inlining CSS like this would not be detrimental to its performance or maintainability.
If you use JavaScript to add or remove the elements dynamically from the DOM when the user interacts with the site. When the browser has finished parsing, downloading, rendering tasks, performance will no longer be an issue. For inlining CSS present in the DOM, as the browser loads the page, inlining should be avoided.
What Type of Inlining Should You Consider?
As the earlier section discouraged a particular form of inlining CSS, you will find another method of inlining that provides higher performance in terms of runtime responsiveness. So, rather than linking to external CSS files like shown below:
<head>
…
<link href=”styles.css” rel=”stylesheet”>
</head>
Directly use the styles (or a portion of them) in the document head as shown here:
<head>
…
<style type=”text/css”>
body{background:#fff;color:#000;margin:0}.link{color:#1a0dab}.ts{border-collapse:collapse}.ts td{padding:0}.g{line-height:1.2;text-align:left;width:600px}.ti{display:inline;display:inline-table}
</style>
</head>
It helps solve the problem where you require the browser to send additional network requests before you can render the page. It also solves the problem of trying to inline and style each element. Giving the element a link class, you can style all the links in the page <a href=”some-link” class=”link”>Some link</a> like you normally do.
You can now lower the number of network requests giving the DOM the various styles it needs for rendering as quickly as possible.
Software development is generally a tradeoff. If you get a better performance, it will be necessary to determine what tradeoff you want to make. While eliminating a network request, you will simply transfer those kilobytes to the HTML file, which will now be much bigger to download (bad).
There’s no such thing as a free lunch! You need to establish a balance for accepting the overhead to get a larger HTML file to eliminate the synchronous network request. On the other hand, if you use several styles in the head, the performance metrics will suffer.
You must observe here that inlining CSS renders a high performance for several metrics including the first contentful paint when we inline the important CSS in the document head (including the keyword being critical). In addition, the site’s stylesheet contains several styles that a user can see as they load your page for the first time.
For example, the styles for the footer are not a necessary feature, if the browser paints the site for the first time. Only the header, hero, and few content styles may be required for the first paint. However, what is displayed in the viewport in the initial load is considered highly “critical”.
As the discussion of tradeoffs proceeds, it will help to eliminate network requests, it will ensure the HTML file won’t get too big. Therefore, it is imperative to know about the hidden advice in having a size limit of 14KB for the different resources for your page.
55. UTM Parameters are Indexed
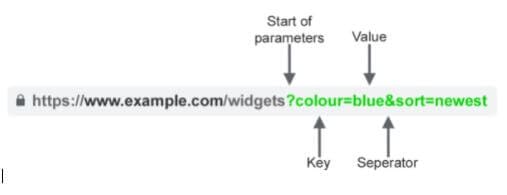
Also known by the other names of query strings or URL variables, parameters are the part of a URL following a question mark. They consist of key and value pairs that are separated with an equal sign. Multiple parameters get added to a single page with the use of ampersand.
The most common use cases for parameters are:
Tracking – For example ?utm_medium=social, ?sessionid=123 or ?affiliateid=abc
Identifying – For example ?product=small-blue-widget, categoryid=124 or itemid=24AU
Reordering – For example ?sort=lowest-price, ?order=highest-rated or ?so=newest
Filtering – For example ?type=widget, colour=blue or ?price-range=20-50
Searching – For example, ?query=users-query, ?q=users-query or ?search=drop-down-option
Paginating – For example, ?page=2, ?p=2 or viewItems=10-30
Translating – For example, ?lang=fr, ?language=de or
SEO Issues with URL Parameters
Parameters Creating Duplicate Content
Many times, URL parameters do not significantly change the content page’s content. It pertains to the re-ordered version of the page, which is often not highly different from the original. Having a page URL with tracking tags or a session ID is identical to the original.
For example, the following URLs will help you to return to a collection of widgets.
Static URL: https://www.example.com/widgets
Tracking parameter: https://www.example.com/widgets?sessionID=32764
Reordering parameter: https://www.example.com/widgets?sort=newest
Identifying parameter: https://www.example.com?category=widgets
Searching parameter: https://www.example.com/products?search=widget
This pertains to quite a few URLs for effective use in the same content. Now, think of this in every category of your site and derive greater value.
The search engines will treat the different parameters while taking into account each URL as a new page when you find several variations of the same page that will serve as duplicate content for targeting the same keyword phrase and the semantic topic.
This kind of duplication would not lead to complete filtering out in the search results. But, it can cause keyword cannibalization and also lower your rank in Google. The overall quality of your site will not get affected by these additional URLs as they do not offer any real value.
Parameters Waste Crawl Budget
The redundant parameter pages will drain down your crawl budget, affecting your site’s ability to index SEO-relevant pages and enhancing the server load.
As per Google-
“Overly complex URLs, especially the ones containing multiple parameters, will lead to problems for crawlers as they create an extremely high number of URLs that will point to identical or similar content on your website. Due to this, Googlebots consume a much higher bandwidth than required, or they are unable to index all the content on your site.”
Parameters for Split Page Ranking Signals
Having multiple permutations for the same page content, links, and social shares could be seen in various versions.
A split page confuses a crawler and dilutes your ranking signals. The crawler becomes unsure of the competing pages that can get indexed in response to a search query.

When the parameter URLs get unsightly, they can be hard to read. Moreover, the URLs would not be treated as being trustworthy. Therefore, they have meager chances of getting clicked.
56. Content Require Interaction
Utilizing interactive content will help to drive engagement and revamp your usual posting process. Moreover, interactive content helps to engage and involve your audience. It also increases the click-throughs and offers greater number of opportunities for educating, informing and delighting your network.
Interactive content comprises any content the user can:
Click on.
Click-through.
Answer.
Play with.
Creating engaging content pieces requires doing more effort or investing a bit more. Nevertheless, if you have such content where users like to spend more time and get a greater value from, the content will be more engaging for your audience. It can also be used to understand your audience better.
Consider the seven types of interactive content to give your audience a better thought process and engagement as listed below.
Quizzes/Polls
Calculators
Contest/Sweepstakes
Multiple Choice Posts
Interactive Infographics, Whitepapers and eBooks
Workbooks and Assessments
Interactive Videos
57. PushState Errors (JavaScript) in SEO Tech Audit
The history.pushState() method is used to determine the changes in the browser’s history. To find such changes in the browser’s history, one can change the behavior of an existing function, also known as monkeypatch using an object known as window.history. This helps make use of our logic to execute when the browser’s history changes the function of history.pushState.
Syntax:
window.onpopstate = history.onpushstate = function(e)
{
// Code to trigger when the history changes
};
58. Insecure Protocol
Here are aspects considered to evaluate insecure protocol in SEO technical audits.
FTP (File Transfer Protocol)
It is one of the highly popular of all the insecure protocols prevalent in use. FTP is the most prominent of all cleartext protocols, and it needs to be used from your network before things go haywire. However, FTP offers a lesser scope for the authentication of your data as it is done in cleartext. FTP was first released in 1971 when the price of gas was 40 cents a gallon. You can well imagine how long ago it was. Therefore, you need to use updated file transfer methods like HTTPS, SFTP, or FTPS. These three protocols help you use encryption on the wire during authentication to the secure transfer of files and log in.
Telnet
If FTP is the king of all insecure file transfer protocols, then telnet is the supreme ruler of all cleartext network terminal protocols. Just like FTP, telnet was one of the first protocols allowing people to administer equipment remotely. Moreover, it became the de facto standard till it was discovered that it passes authentication using cleartext.
For this, you have to find all equipment that is still running telnet and replace it with SSH, using encryption to protect data transfer and authentication. This shouldn’t be an overwhelming change if your gear cannot support SSH. However, several appliances and networking gear used in running telnet require the service to be enabled or get OS upgraded.
When both the options are not appropriate, you will need to get case loading of new equipment. Money can be an issue several times, but certainly, it’s no point wasting your resources on a half-century-old protocol running on your network, which is challenging to update. At such times, you need to think about which priorities are most important for you. In no case do you want to gain control of your network via telnet, or the game is over.
SNMP (Simple Network Management Protocol)
SNMP is again one of those protocols you least suspect to give you a problem, but it is the one that might undoubtedly be problematic of those sneaky protocols that you don’t think will be a matter of great importance! escort date escorts
There are several versions of SNMP, and you must be particularly careful with versions 1 and 2. People that are not familiar with SNMP must use it as a protocol enabling the management and helping in the monitoring of remote systems. Again, you can send the strings via cleartext. If you get access to the credentials, you must connect to the system and gain a foothold on the network- for managing, applying new configurations, and achieving in-depth monitoring of details of the network. Overall, it will help the attackers if they get hold of these credentials.
Fortunately, version 3.0 of SNMP provides enhanced security to protect you from all these attacks. First, review your network and ensure that SNMP v1 and v2 are not being used.
They are a few of the more popular and insecure protocols which are still highly used among the various networks today. An audit of the firewalls and systems helps you identify these protocols and help you use an automated tool like AlgoSec Firewall Analyzer. It will help you enlist these protocols rather quickly in your network. Moreover, it is also essential to proactively analyze every change to your firewall policy (again, preferably with an automated tool for security change management) to ensure no one introduces insecure protocol access without proper visibility and approval.
Finally, don’t feel bad telling a vendor or client that you won’t send data using these protocols. If they’re making you use them, there’s a good chance of compromising other security. It is time to say goodbye to these protocols.
59. HSTS
HTTP Strict Transport Security (HSTS) is a web server directive informing the user agents and web browsers how they handle its connection using a response header present at the very beginning and back to the browser.
It helps in setting the Strict-Transport-Security policy field parameter while forcing these connections over HTTPS encryption. It disregards the script’s call for loading any resource in the domain over HTTP. HSTS is like an arrow present in a bundled sheaf of security settings for the webserver or the web hosting service.
Reasons to Implement HSTS in Your Company.
Do you ever sleep in your physical home or close your physical store without locking the doors?
Of course, never! Instead, some of us may even install metal detectors at the entrance to control shrinkage. Similarly, your data is also valuable, like the other physical items present in your shop or house. Therefore, it is important to keep things locked up and secure. Instead, it is sometimes not enough to padlock your website as people can find alternative routes to reach your website over HTTP://. So, HSTS forces browsers and app connections to open HTTPS if it is available even when someone just types www or HTTP://.
HTTPS is a small ranking factor in Google which categorizes websites for ‘site quality score’ with several factors like page speed and mobile responsiveness.
Things to Understand
It may not be enough to set 301 redirects from HTTP:// to HTTPS://to secure your site’s domain name completely. There may still be an opportunity for encryption in the insecure redirection of HTTP.
$ curl –head http://www.facebook.com HTTP/1.1 301 Moved Permanently Location: https://www.facebook.com/
The hacker(s) can capture site cookies, session ID (usually sent in the form of a URL parameter), or forced redirection to a phishing site that looks like your website.
With the installation of the Strict-Transport-Security header, it may be impossible for the attackers to take out any information!
$ curl –head https://www.facebook.com HTTP/1.1 200 OK Strict-Transport-Security: max-age=15552000; preload
How Popular Is HSTS Implementation?
The multi-billion-dollar company, Google, formally rolled out an HSTS security policy on July 29, 2016.
The HSTS project was initially drafted in 2009. and it became a memorandum on June 08, 2015.
All major social networking and payment portals, including Facebook, Google, Gmail, Twitter, and PayPal, have implemented HSTS today. There has been the M-15-13 Policy that Even the United States Government, Executive Office of the President to secure Connections across Federal Websites and Web Services. The complete HSTS project was initially drafted in 2009.
How to Implement HSTS for Your Website
It would be best if you used subdomains in your content structure, using a Wildcard Certificate that covers HTTPS. Or it would help if you used a Domain Validated, Organization Validated, and the extended Validation SSL Certificate. HTTPS and SSL certificates should be properly installed and in working condition.
Firstly, they will test your web applications, user login, and session management. It will be set in such a way that your HSTS will expire every 5 minutes. Always test HSTS for one week to one month. Make sure to fix any issues arising in the deployment. Modify max-age; one week = 604800; One Month = 2592000. As tests give successful results, change preloads.
As you get confident that HSTS is compatible with your web applications, modify the max-age to 63072000 as per The Chromium Project, which is of two years.
The Important HSTS Requirements
Post-February 29, 2016, these requirements have been in effect.
Your website must have a valid SSL Certificate. GlobalSign’s SSL Checker is the place to check the validity of your SSL
Use a 301 Permanent Redirect from your HTTP links to HTTPS ones.
Make sure your SSL certificate covers all the subdomains. A Wildcard Certificate is a better choice.
You need the HSTS header for the base domain of HTTPS requests.
Set the max-age to be at least 10886400 seconds (18 Weeks).
You will need SubDomains directives with specifications if you have them!
Make sure the preload directive is specified.
If you do not comply with these requirements, chances are your listing will get removed. In any case, when you need to remove your HTTPS-only domain, always go through the guidelines thoroughly first.
60. No DOCTYPE Declaration
The HTML standards rely on doctype or “document type declaration” (or “doctype”), which is an instruction to the web browser indicating the version of the markup language in which the page is written. The doctype is an important part of the standards-compliant web pages.
Doctype also specifies the modern browsers how they should apply CSS and HTML standards in rendering a page. It includes the most contemporary versions of Chrome, Firefox, Internet Explorer, Opera, and Safari. The doctype can also include Document Type Definition (DTD), which specifies the rules for a markup language, specifying that browsers must render the content correctly.
If there is an invalid or nonexistent doctype specified in the HTML page, browsers can go into the “quirks’ ‘ mode, the page, the browser can handle the markup differently and is outdated.
You will find it in Logi Studio that the doctype gets configured using the Doctype Declaration attribute having the General element in the _Settings definition. There are five options available for using the pull-down selection list.
In v11.0.416, HTML5 offered a choice in the drop-down list of several doctype options. It was the latest default value when no DocType Declaration value got entered or selected.
In v10.0.337, lets you type directly in the different custom doctype statements, including the following <!DOCTYPE HTML> for HTML5, as it was introduced.
No doctype instruction gets added to the Logi Server Engine generated HTML pages if none is selected. The other four options can be discussed individually in several sections.
HTML5
As this option gets selected for the Doctype Declaration attribute, <!DOCTYPE HTML> is placed at the start of the generated HTML page:
HTML5 is the fifth revision of the HTML standard and is not based on SGML. It does not require a reference to a DTD like various doctype declarations. The core of HTML 5 aims to better the language and add support to its latest multimedia content.
It keeps the code easily readable by humans, and computers and other devices can easily understand it. HTML5 is meant to take care of not only HTML 4, XHTML 1 and DOM Level 2 HTML.
XHTML Strict
Doctype Declaration attribute choosing this selection, uses <!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Strict//EN” “http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd“> at the start of the generated HTML page:
It means the document in the XML version or a trimmed-down version of HTML 4.01 Strict. This version emphasizes structure over presentation. It includes the deprecated elements (like font) and attributes (most presentational attributes), link targets, and frames that are not allowed in HTML 4 Strict Style can be applied using style sheets.
HTML 4 Strict will enable developers to achieve much. It can be accessible and structurally-rich reports for quickly adapting to varied browsing situations and style sheets. On old browsers, HTML 4 Strict documents still look bland on the old browsers, not supporting style sheets.
XHTML Transitional
When <!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN” “http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd“> is placed at the beginning of the generated HTML page while choosing Doctype Declaration attribute, it declares the document to be the XML version of HTML 4.01 Transitional.
It includes all of the elements and attributes in HTML 4 Strict for adding deprecated elements, presentational features, and link targets. Moreover, one can use style tags which can be included right in the HTML.
XHTML Frameset
This is the default option in the Doctype Declaration attribute and ischodsen if the pace is left blank. In this, <!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Frameset//EN” “http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd“> is placed at the start of the generated HTML page:
It means the page is the XML version of the HTML 4.01 Frameset, which includes the various attributes and elements of the HTML 4 Transitional version. It is considered the most “generous” doctype for supporting the maximum number of features in the HTML document.
What’s the Impact?
The choice of a specific doctype can have a significant impact on a Logi application.
The XHTML Frameset provides a “loose” standard covering everything, right from the HTML generated by the Logi Server Engine that typically didn’t lead to DTD-related problems. This was before v11.0.416, which is now treated as the default option.
In v11.0.416, HTML5 is the default option, and it can significantly render differences in various browsers.
If you do not select any doctype, you will see CSS presentation differences in the various browsers. But, things would not get aligned correctly. Thus, the right style would not get applied in the way you expect it. This indicates a large number of problems to occur in Internet Explorer.
When you get a complementary action, it allows you to see the differences in how several browsers will be present in your report pages. Using doctype brings uniformity in this.
Studio will automatically insert the default doctype, XHTML Frameset or HTML5. Following this, open and edit the legacy report definitions, based on the Logi version, into the definitions. This will help you to understand when to upgrade your application to Logi v10 or 11. It will generally lead the CSS to work differently, causing the resulting reports to look different. Developers that look forward to great reports must “correct” these effects to set the doctype to None to get the reports in their original appearance.
Before HTML5, only the developers could be using XHTML Strict doctype as it became possible. The “tight” standard requires that you code things with great accuracy. If you use Event Handler with Action.Javascript (v10.0.259+)or Action.Link and Target. Link elements (earlier versions) in the Logi app and add Javascript always use the right case-sensitive spelling for the various Javascript functions. For example, “getElementById()” will work, but “GetElementByID()” will not.
Your doctype choice will also affect the different HTML documents you want to embed in your Logi application. Here, the HTML is not generated by the Log Server Engine, so you must take care that the coding is compliant with the selected doctype. For example, if you’ve embedded the HTML document in the <font> tag, you must choose the Strict doctype. Or the tag gets ignored because the doctype does not provide for presentation-related tags in the HTML.
61. Missing XML Sitemap
The sitemap is the website page that directs the search engines to all the essential pages on your site. You can easily add the sitemap in the Yoast SEO plugin. However, there can occur several kinds of errors in the XML sitemap structure. The commonest ones are:
Missing of the required tag: The solution lies in adding it and resubmitting it.
This error appears if the sitemap has zero items. The correction step means that you must create content for the sitemap. But, if you know that you have made new content, take all the care to clear/flush the cache from your website, plugins, themes, servers, and more.
It generally occurs in the Video SEO sitemap or News SEO sitemap if no videos have been made or if the new website has not published a news article within the last two days. It can also happen with the https://yoast.com/help/sitemap-error-missing-xml-tag/.
There can be other errors as well. Check this article with the list of common XML sitemap errors to find out more errors, their underlying reasons, and the corrections that may get applied.
62. Missing Assets on XML Sitemap
Google considers various sitemap formats. Nevertheless, XML is the most commonly used sitemap format. You need to create sitemaps for
Web pages,
XML files
Image and video assets.
You can generate a sitemap manually or employ a third-party tool to build one.
How to add XML Sitemap to Your Site?
Use the XML format to save the file extension (i.e., “sitemap.xml”).
Upload the file, thus saved to your website.
How to Submit the XML Sitemap to Search Engines?
Test your sitemap using Google Search Console. Go to the Crawl section, click on Sitemaps. Add a test and submit a sitemap.
63. XML Sitemap Not Findable
General Sitemap errors- Yoast
|
Error |
Cause |
Solution |
| sitemap URL format error. For example, if a sitemap does not include/exclude www or has http instead of https. | The sitemap uses the correct protocol like the WordPress Site URL. | Correct protocol like this. Go to Admin > Settings > General and change the site URLs. See if you may have incorrectly formatted URLs in your database, especially if you have recently switched your URL format. You also have to backup your database and carry out a search to replace the format with the new one. |
| Sitemap is a header with no URLs or a white page | 1.Your XSLT file is not accessible. 2. The XML is invalid 3. “Do not process 404 errors for static objects with WordPress” setting is chosen in W3 Total Cache. |
Check this page to see which error applies to you, and fix it accordingly. |
| Sitemap not functioning on an Apache server. | Chances are, the new Yoast rewrite rules are not implemented. | Refer to this article to troubleshooting the sitemaps present on Apache servers. |
| Sitemap does not function on an NGINX server. | Chances are, the new Yoast rewrite rules are not implemented. | Refer to this article to troubleshooting the sitemaps on NGINX servers. |
| The plugin is not creating a sitemap. | The permalinks settings aren’t properly saved. | You need to save changes in WordPress. Do it like this. Go to ‘Settings’ , then Go to ‘Permalinks’, then Click ‘Save Changes’ (do not alter anything). |
| The sitemap has gray links. | Moz built the sitemap in this way. | Gray sitemap links identify recently visited URLs of your browser. Google overlooks the browser formatting because it retrieves the XML source code. Read more about gray links in this article. |
| New videos are added at the end of the second sitemap. | This is inbuilt. | It helps Google and saves crawl time and effort. Google just needs to re-fetch those videos instead of re-fetching the video sitemaps at all times. Google knows what’s new with the last update. |
| Sitemap does not update. | The cache functionality on your site might be preventing the sitemap from automatic updating. | Refer to this Yoast article to get more advice and insight into tackling this issue. |
| Cannot see a particular page in my sitemap. | Several reasons an individual page is missing from the XML sitemap: 1. The page (or the whole post type) is set to noindex. 2. The canonical URL of the page is set to a different URL. 3. The page gets redirected to another URL. 4. In news sitemaps, the pages that have not been published within the past 48 hours cannot be seen. |
Checklist of to dos for fixing: 1. Find if any individual page is set to noindex. Navigate to the Advanced tab in the Yoast SEO metabox, to make sure that you’ve allowed search engines to display the page in the search results. 2. Have a look at settings for the whole content type/taxonomy, navigate to Search Appearance settings . You shouldn’t be blocking search engines from accessing your content. 3. Ensure that the page’s canonical URL is set to a different URL. For this, use URL inspection tool and make sure to comply with Google’s guidelines for consolidating duplicate URLs. 3. If you use Yoast SEO premium, access its redirect manager to find out if the page gets redirected to another URL. |
64. XML Video Sitemap Missing
This sitemap offers additional information about the videos hosted on your pages. This sitemap provides a superb way to assist Google in finding and understanding the video content present on your site, especially if the video content has been added recently. Or it something we could not see with the usual crawling mechanisms. It is present in the form of Google Video Sitemap, an extension to the Sitemap standard. Google recommends the use of video sitemaps.
The basic guidelines for video sitemaps are as under:
It is possible to create a different sitemap for a video, and you can embed the video sitemap in an existing sitemap, whichever of the two provides more convenience.
It will allow you to host multiple videos on a single web page.
Every sitemap entry is present in the form of the URL of a page hosting one or more videos. Here is the structure of each sitemap entry.
<url>
<loc>https://example.com/mypage</loc> <!– URL of host page->
<video> … information about video 1 … </video>
… as many additional <video> entries as you need …
</url>
65. XML Sitemap is Too Large
If you have very large sitemaps, split them up. It is sensible to use the sitemaps index file to submit them in a go. The sitemap index file and sitemap file have quite similar XML format. The sitemap index file uses the following XML tags:
Sitemap index – the parent tag surrounds the file.
Sitemap – the parent tag for each sitemap listed in the file (a child of the sitemap index tag)
Loc – the location of the sitemap (a child of the sitemap tag)
The Sitemap Protocol page provides you with more excellent information on the syntax.
In addition, see the XML format sitemap index for two sitemaps, below.
<?xml version=”1.0″ encoding=”UTF-8″?>
<sitemapindex xmlns=”http://www.sitemaps.org/schemas/sitemap/0.9″>
<sitemap>
<loc>http://www.example.com/sitemap1.xml.gz</loc>
</sitemap>
<sitemap>
<loc>http://www.example.com/sitemap2.xml.gz</loc>
</sitemap>
</sitemapindex>
Submit your index file to Google as you made and saved it. It’s only done when you upload and save all the sitemaps in the same location as on the host server.
How are Many Sitemaps Index Files Allowed?
It is possible to submit 500 sitemap index files for every single site in your account.
Sitemap Management for Multiple Sites
Web admins owning multiple websites can simplify creating and submitting sitemaps as they make and save one or more sitemaps having URLs for all the verified sites. You need to keep the sitemap(s) to a single location. All sites must be verified in the Search Console. You can choose to use:
A single sitemap will include URLs from multiple websites, like the sites from different domains. This can include the sitemap location at http://host1.example.com/sitemap.xml can consist of the following URLs.
http://host1.example.com
http://host2.example.com
http://host3.example.com
http://host1.example1.com
http://host1.example.ch
Individual sitemaps present in a single location.
http://host1.example.com/host1-example-sitemap.xml
http://host1.example.com/host2-example-sitemap.xml
http://host1.example.com/host3-example-sitemap.xml
http://host1.example.com/host1-example1-sitemap.xml
http://host1.example.com/host1-example-ch-sitemap.xml
66. Is XML Sitemap Malformed?
XML sitemap files signal the search engines indicating the pages that need to be crawled. Therefore, it is important for large websites containing images, videos, and news with well-formed, clean and optimized sitemap files.
Few SEO Issues with Sitemaps:
Malformed XML markup. The sitemap markup gets broken and cannot be parsed by search engines.
“Dirty sitemaps” – XML sitemaps comprise links to URLs with redirect errors and other issues like a non-200 status code (broken links, redirects, internal errors). These are URLs that sitemaps should not crawl.
Website sitemaps contain links to non-canonical URLs-the ones returning the status code 200, leading to a lot of wasted technical resources/crawl budgets on unimportant pages.
67. XML Sitemap has Non-Indexed URLs
It means that the said URL in question is noindex, but it is included in the XML Sitemap.
What you need to know
The XML Sitemap contains only the URLs that you want the search engines to index. Noindex URL indicates to the search engines that you do want the URL to be indexed.
It is a piece of conflicting information to search engines that may result in unwanted URLs getting indexed.
What is the Hint check?
This Hint will begin forming an internal URL set to noindex, and it will be included in the submitted XML Sitemaps.
For example, consider the URL: https://example.com/page-a. It is present in a submitted XML Sitemap.
The Hint triggers for this URL if it gets a noindex in the <head> or the HTTP header (or in both):
Meta noindex in the <head>,

Resolving the Issue
This Hint, when it gets marked critical, represents a principle-breaking issue. This can harm organic search traffic. Therefore, Critical issues should be taken as a matter of high priority.
The present setup may not be technically correct, and it may lead to technical indexing issues.
You will require dealing with this using one of the following approaches:
- If the URL should be noindex, then remove it from all XML Sitemaps. Once removed, resubmit the sitemaps on Google Search Console.
- Remove the noindex tag of the URL.
68. Outdated XML Sitemap
The outdated sitemap may not affect your rankings directly because the penalties and the other things are sure if you do not comply with that. But suppose you talk about this in general. In that case, your rankings will go down because the algorithm of the fetching data can change with time, while your outdated sitemap may hinder getting the data it requires for updating the current ranking values.
It is more of a secondary effect that would hurt you in the long run. But you do not incur any specific penalties for it.
69. Inline / On-Page CSS
The people that created CSS have, in basic ways, can use CSS in the web pages. The three ways to insert CSS into your web pages.
1. Via an External File that You Link to in Your Web Page
| <link href=”myCSSfile.css” rel=”stylesheet” type=”text/css”> |
or using the import method:
| <style type=”text/css” media=”all”>
@import “myCSSfile.css”; </style> |
Suppose you use the import method against the link method while using external style sheets; you can also use the import method to want the old browsers, including Netscape 4.0 truly.
Netscape cannot handle most of the CSS beyond font settings and colors. Therefore, if you find other types of CSS, it will result in the Netscape 4 crashing on some occasions, or it might mangle your page.
You cannot apply the @import method for linking to the stylesheet, unlike the new browsers. As a result, Netscape will ignore the request. So proceed to hide the fancy CSS code in the external style sheet using the @import method so that all the best browsers can reference it and keep Netscape 4 away.
2. Create a CSS block in the web page; insert it at the top of the web page in between the <head> and </head> tags:
| <head>
<style type=”text/css”> p { padding-bottom: 12px; } </style> </head> |
3. Insert the CSS Code on the Tag Itself.
| <p style=”padding-bottom:12px;”>Your Text</p> |
Here are the three methods of including the CSS in a web page? Precision is the most essential factor for this.
Method 1: Create a separate CSS file to link it to your web page(s)
A separate CSS file will be used to link pages. Just type in the CSS code on the web page itself. Then, while you keep the CSS code in its original file, you can link the CSS file to the different web pages in the way you want. It serves you two crucial advantages:
- It results in much less code in various HTML pages – making them precise and easier to manage. So, you can download the web pages a bit faster.
- It tremendously lowers the amount of work you need to do. For example, if you have 50 web pages that require you to set the text as black, you have to set the headline text to blue. On a particular day, you want to change the text color as the CSS controls the text color of all the 50 pages in a single CSS file. Changing a single line in the CSS file will help you quickly change your text color in all 50 pages!
Imagine, if you had included the text color information on each page, you would require making the changes on all 50 pages. But, of course, things could worsen if you had been using CSS on each tag; it would alter the color settings code on all the <p> and <h3> tags in all 50 pages; it would have indeed made it a clumsy task to change text color.
Pro Tip: If you have a cluster of web pages having similar stylistic properties, create a separate CSS file to link your web pages to it.
Method 2: A CSS block in the web page itself
Apply this method to override the CSS you have in a linked CSS file or have a single-page website.
‘Cascading Style Sheets.’ stands for cascading style sheets. Let’s understand what ‘cascading’ in CSS means? We describe it ahead.
The Cascading Effect in CSS
The word ‘cascading’ in CSS describes a cascading mechanism, which means the CSS code on a page itself will override the CSS code in the differently linked file. Later on, CSS declared ‘inline’ on the tag would help to override all the CSS.
Suppose you have a website of 50 pages with similar stylistics of layout and fonts. Put the CSS information setting the layout and font choices in the discrete style sheet.
However, if you need to change the color of a part of the text or add a specific feature like a border around the paragraph on a particular page. So, a little CSS in the page itself can help you get unique stylistics on that page.
Method 3: Embed the CSS right on the tags themselves (called inline CSS)
The Rule: This method will help you get the unique element/tag impacted with CSS.
For instance, in the case of a particular heading on the page, that requires having a little more padding. Here, in place of creating a class elsewhere that gets used only on one occasion. So, in this case, it’s enough to include the CSS inline, which is otherwise rarely used.
70. Additional On-Page JavaScript Issues
JavaScript SEO includes everything you want to create a JavaScript-reliant website with excellent performance in search engines. It is one of the specialized Technical SEO aspects.
Why You Need Javascript SEO
Developers just love JavaScript because it is an incredible tool and like its features like AngularJS, Vue, Backbone, or React. JavaScript lets them create highly interactive web pages.
On the other hand, SEOs do not make a very good impression of JavaScript regarding your website’s SEO performance. Much work needs to be done for JavaScript-enabled sites that show a sharp decline in organic traffic when they begin to rely on client-side rendering.
What is the Way Out?
Developers and SEOs must collaborate effectively to achieve great outcomes. In the end, they need to come up with results that give the visitors and search engine robots the best possible experience in JavaScript-reliant websites.
It means that search engines should be able to comprehend what your pages are about and if your crawling and indexing guidelines are derived from an initial HTML response.
71. Excessive Inline JavaScript
Inlining is the script tag that is used in the HTML file. It indicates that no external JS file is used in its place; Javascript is placed in the HTML file.
From manual coding that was used earlier, the modern code now has ushered into customized structures and templates, providing a framework for an effective code creation process. This is especially required on the front-end code.
Does it Make Sense to Use Inline JavaScript in HTML?
Javascript is functional in places and locations like mobile devices, TV screens, and wearable devices. It has now evolved beyond the original promotional scope.
Regarding JavaScript in the web and the DOM manipulation, we can go far ahead in terms of its architectural setup, version releases, and handwriting of inline JavaScript and beyond the traditional beyond.
How to Inline Javascript?
When you want to add an external JavaScript sheet, it makes sense to use the <script src = “”> tag regarding where you reach in the middle of the file.
The browser can
Read the entire HTML document from top to bottom
Drag and load your JavaScript file appropriately.
Start the script accordingly.
It means that when you place the JavaScript call in the top and head area, the script gets executed immediately as the DOM loads.
In the case of a few external scripts, the DOM elements load first. Therefore, it is recommended to place the script-src call at the bottom.
If you write inline JavaScript, it is similar to the src tag, except that the code is just inside the HTML file, and it is not called externally.
Just copy the content of the external javascript file to paste it between the script tags of the HTML file like this:
<script>
YOUR JAVASCRIPT HERE
</script>
72. Invalid HTML Markup in Technical SEO Audit
HTML specifications have become renewed, with many of the old ones becoming obsolete. What are HTML elements you should not be using, and if you are, what can you do to fix the problems associated? The following list also includes alternate tags you can use:
applet: Using this tag can land you in a bigger problem than the use of a deprecated tag as Java is now becoming more and more redundant as a web programming language. Switch to the embed element or object for a short-term solution. In the long term, stop using Java on the website.
bgsound: As the name indicates, this element is related to music or sound on the website. IE used it to add background music to websites. But, it isn’t a good idea to use background music on your site. Never do it. Rather, add audio content to your site using the audio tag, and keep in mind that autoplay is the worst option ever.
frame: The frame element has been removed from the HTML specification alongside the other elements associated with it. In place of frame , use an iframe to embed external web pages and CSS while designing a website layout.
hgroup: Earlier on, it was possible to group a title and subtitle, putting them together in the appropriate heading level using hgroup tags. However, this element is now deprecated. What you should do
Use a single heading element to include both the title and subtitle.
Wrap the subtitle in span tags.
Use CSS to control the styling of the subtitle.
dir: The directory element is now obsolete, and it was used to store a list of files or pages. It is best to use an unordered list of anchor elements in place of the dir element.
acronym: Use the abbreviation tag abbr in place of this deprecated element.
isindex: This element was used for creating a text field on a web page. But, a better way of doing it is using the form element input with the attribute type=” text”. isindex is obsolete as of HTML 4.01.
plaintext, xmp, and listing: These tags include the vivid ways of displaying text in plain text instead of HTML. There are two options, pre and ‘code’, to embed plain text in the HTML document.
For monospace font display, use pre
To display code, use the code element.
Do away all < and > symbols replacing respectively with < and >
73. Checking Missing Micro Formatting
Microformats form a part of structured markup. Simply put; microformats are bits of code that help the search engines to access the right information on your website.
Microformats are kinds of “labels” for the different parts of your content. For example, if your business has loaded an event on its website, microformats will give details to Google-“This is the event name,” “this is an event venue,” “this is the topic to be discussed,” and “this is the speaker.” and so on.
For products on websites, microformats are used in reviews to tell search engine ratings, customers’ opinions, and more.
Microformats and SEO
Google uses microformats to generate a rich snippet for your SERP listing. Microformats help Google search your site differently. It goes beyond the monotonous manner of listing being just the title, URL, or a random description from a page. It gives the most important and most valuable information like your restaurant’s most popular recipe, its reviews and rating, your book’s ratings and reviews, or a recipe. It can also display the hours of operation or your location. The unique information evokes the interest of the users and gives them pieces of information to chew on. It naturally brings about an improved click-through rate and is excellent for your SEO.
74. Lack of Body Content
The <body> element can be considered as the most important HTML element. The <body> element contents get displayed to the user visiting your web page.
The body element is the most simple to comprehend and implement. in <html>the <body> must come after <head> if th latter is present, or the <body> can be present alone..
Styling the <body>
In the earlier HTML versions (and in some proprietary browser markup schemes), you could find many styling attributes for the <body>. But, in HTML 5, these have all been deprecated. So, you need to put any styling of the <body> into your CSS.
Why is this so good?
<body> is an excellent place to put all the CSS that can affect the overall document display: The stylistics you can include are
fonts and typography
Text
Background colors
And other “default” styling.
body { font-family: “Adobe Garamond Premier Pro”, Garamond, “Linux Libertine”, Baskerville, Georgia, serif; font-weight: normal: font-size: 18px; color: #111111; background-color: #fefefe; padding: 1em; width: 95vw; max-width: 950px; margin: 0 auto; }
How Should you target the <body>
A standard content management system practice involves placing certain content-specific CSS classes into the <body> element. It helps JavaScript developers and designers to target pages according to their specific content attributes(content type, category, tags).
<body class=”post post-single post-template-default tag-html tag-element tag-document category-markup category-html post-123 with-comments social-sharing-on logged-in”>
75. Text Contained Within Images
Text Contained Within Images is also known as “alt tags” and “alt descriptions,”
if an image does not load on a user’s screen, a written copy appears in place of an image on a web page. This text serves these purposes:
It helps screen-reading tools describe images to visually compromised readers
It facilitates the bots to crawl better on your website.
It makes complete sense to optimize your website’s image alt text because it will create a better user experience for the visitors, irrespective of how they found you initially.
Adding Alt Text to Your Images
Most content management systems (CMSs) allow you to alter to add alt text to your images simply. Just click on an image present in the blog post. Now, it becomes available for its optimization in the rich text module. In other words, you can create and alter the image’s alt text.
An image optimization window looks like in the CMS of the HubSpot portal:
The alt text you apply to the image gets automatically written into the web page’s HTML source code. If your CMS doesn’t provide an easily editable alt text window, go to the HTML source code to change the image’s alt text further.
See below to get an idea.
While creating an alt text, always be descriptive and specific. Furthermore, it is vital to consider the image’s context while choosing the written text for alt description.
76. Generic Anchor Text
Anchor text is an essential detail in SEO. It refers to the text you click to navigate from one internet destination to another. It derives its name as it anchors together with the different locations present on the internet.
The anchors typically will generally link web pages. Moreover, the anchor text can also take care of the download and link the documents, including PDFs, present in Google Drive. So, you must click only the anchors from sites you trust. You can find the site by hovering over the link using your mouse! Click only if the URL looks legitimate.
Here is an example:
Semrush is the all-in-one kit for digital marketing professionals.
In the above sentence, “Semrush” is the anchor text. However, as you hover around the linked word with your mouse, you find that it links to the Semrush homepage and not an unknown malicious file.
Choosing the Text for Anchors
- It informs your readers what they can expect when clicking the link. Anchor words are like a window to what is present on the other side of the link. So, the anchor text must be highly relevant.
- Google’s algorithms will analyze your anchor choices to determine that you are not engaging in spammy practices. The anchor text also tells the Google algorithms what your content is about.
77. Content on Subdomain
Distinguishing between the main domains and subdomains is a difficult task. In a few places, people generally combine the two—however, it’s essential to know that they are entirely different.
The main domain is also known as the primary domain or the root domain. It essentially comprises the name of your website.
For example, for Brafton’s website, the primary domain name is brafton.com. It is not www.brafton.com or https://www.brafton.com, which are technically the URLs.
The subdomain is a part or the extension of the website that can be marked with its unique identity and content. For example, if Brafton creates a subdomain for its blog page, the subdomain would be named blog.brafton.com.
You might question the utility of dividing the different areas of your website into subdomains. Here is an example of how it helps to build site hierarchy:
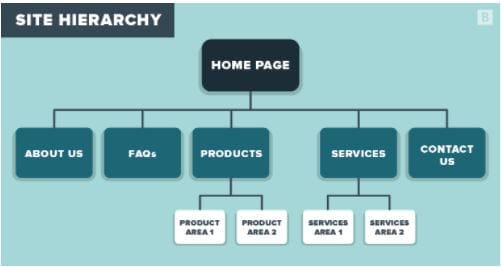
78. Dynamic URL Issues
When the content of a site gets stored in a database, and it gets pulled for its display on the pages on demand, dynamic URLs can be used. In this situation, the site will basically serve as a template for the content. Typically, the dynamic URL generally looks somewhat like this.
The dynamic URLs quill have characters like:
? = &
Dynamic URLs are associated with the disadvantage that the different URLs have the same content. The various users can link to URLs having other parameters but the same content. This is the reason why webmasters like to rewrite their URLs to static ones.
79. Internal Linking Issues
Internal links hold a great value in SEO. Google makes use of internal links to discover new content.
For example, if you publish a new web page and miss linking to it from another location on your site, it is assumed that the page in question is not on your sitemap because it doesn’t have any backlinks. Therefore, Google does not know if the page exists as the web crawler cannot find the link.
Google constantly searches for new pages to add them to its list of available pages. Google news a few pages because Google has crawled them earlier. At the same time, the other pages get discovered as Google follows links from known or already crawled pages to new pages.
Pages not having internal links pointing to them are known as orphan pages.
Internal links also help in the flow of PageRank around a site. It’s undoubtedly a big deal. In general, the more internal links in a page, the higher the PageRank is. In the end, it’s not just about the quantity; but it is also the quality of the links that play a vital role.
80. Jump Links usage to Link to Pages
Jump links are in-page links and are also referred to as anchor links. These links lead the users to link the content on the same web page in place of another page of the site. Earlier on, the user-experience recommendation was to avoid such kinds of links. But, now the scenario is different, using in-page links increasing in a few years. Jump links are getting popular in web design, so a deeper evaluation of the actual benefits and disadvantages of the jump links is worth the while.
The Concern with the In-Page Links
There is a primary usability-related concern wrt in-page links. It is believed that they do not meet users’ expectations for a mental model for a link. Typically, links lead to another page; if it happens another way, it will confuse and distract the users.
How is This Balanced?
This usability concern can be balanced by bringing into the picture the usability-related benefits of the in-page links. In general, the in-page links help users navigate through page content relatively quickly. For example, these may be links leading to information present further down in the page can:
They will act as a table of contents that will help the users form a mental model of the page.
Give direct access to users to their content of interest.
Improve discoverability of the content that requires a long scroll to reach (in long-form content). It also increases the engagement of the users.
There Common Uses of Jump Links
You will generally find the jump links in a single web page with the following:
Tables of Content: Jump links are generally used in content for longer pieces of content. It helps the readers get direct access to the content of interest.
Back to Top: You have seen the Back-to-top links, haven’t you? Click on them, and you will reach the top of the page from a different part of the page. These links offer functionality like that of a scroll bar; they can be helpful on long pages. Just with a single click, you will save time for multiple scrolls. These links should not cover the content. Though even if they do, it won’t cause any huge problems). On the other hand, they will help the users who do.
Indexes and FAQs: in-page links will be of great use in Alphabetical or numeric indexes or lists of frequently asked questions. When a website has a list of links at the top or in the introduction, it helps users scroll through numerous items to the topic, which serves them well. Many times, users need a specific piece of content, and it helps them save time if they can reach the content with an in-page link rather than scroll all the way through.
Saks.com offers an alphabetical index to allow users to navigate directly to a letter in a list of designers. Here the A-Z list allows direct access to the designer of interest.
https://www.nngroup.com/articles/in-page-links/
81. Improper Lazy Load Implementation
The practice of delaying the loading or the initialization of the resources and the objects till they’re actually required is supposed to improve performance and help in saving system resources. When a web page has an image that the user must scroll down to see, use a placeholder to effect a lazy load for the whole picture. It means the image will load only as the user arrives at its location.
The advantages of Lazy loading:
Lowers the initial load time – Lazy loading a webpage lessens page weight, allowing a faster page load time.
Bandwidth conservation – Lazy loading saves bandwidth as it delivers the content to users only when it is requested.
System resource conservation – Lazy loading also saves the client and server resources, as just some of the images like JavaScript and other code require to be rendered.
82. Technical SEO Audit of Internal NoFollow Links
Google introduced the nofollow link attribute in 2005. No follow links were brought into the picture to counter the spammy links that were being used to dodge the system. However, in the present scenario, Google considers the nofollow link attribute like a hint instead of a directive.
Google has also introduced two other attribute values to complement the nofollow link attribute in its bid to distinguish the origins of non-natural links.
rel=”sponsored” (paid and sponsored links)
rel=”ugc” (user-generated content links in comments, forums, and message boards)
Typically, the nofollow link attribute is applied to unnatural links if the website owner wants to refrain from association with the link’s target URL.
83. Audit of User-Facing Sitemap
A user sitemap helps users navigate the website with the listing and link to significant parts of the content. Moreover, user sitemaps are beneficial for visitors to land the information they’re looking for quickly.
84. Relative vs. Absolute URLs
Absolute URLs
An absolute URL comprises the full address, right from the protocol (HTTPS) to the domain name (www.example.com). Plus, it also includes the location present in your website’s folder system (/foldernameA or /foldernameB) in the URL. In other words, it is the entire URL of the page you’re linking to.
An example of an absolute URL is:
<a href = http://www.example.com/xyz.html>
Relative URLs
The relative URLs do not use the full web address. They have the location and the domain. These assume that you add the link, which is a part of the same root domain and is on the same site. The relative path begins with the forward slash and helps the browser to stay within the site.
An example of a relative URL is:
<a href = “/xyz.html”>

(More of a visual learner? The above is a helpful sketch of the differences between relative and absolute URLs.)
Advantages of Relative URLs
Faster Coding
It can become effortless to code large websites when you shorten the URL to a relative format.
Versatile Staging Environment
While using a content management system featuring a staging environment with a unique domain like WordPress or SharePoint, your whole website gets replicated on that staging domain. A relative format will let the same website be present on:
Staging domain.
Production domain.
The live accessible version of your website.
No need to backtrack and re-code the URLs. This helps a web developer to save the coding efforts as well as time.
Faster Load Times
Relative URLs allow faster loading of pages in comparison to pages with absolute URLs. However, the difference may seem minuscule for the most part.
Advantages of Absolute URLs
Discourages Scrapers
URLs that absolute method prevent people from scraping information from your site’s directory. If all of your internal links have relative URLs, it becomes so easy for the scraper to just scratch your entire website to put it up on a new domain.
Does Not Allow Duplicate Content
Absolute URLs help you to avoid duplicate content issues when you have multiple versions of root domains for indexing in Google without the use of canonical tags pointing to the correct version of the site.
For example:
http://www.example.com
http://example.com
https://www.example.com
https://example.com
Google considers them as four different sites. Google can possibly enter your site accessing any one of these four pages. Now, if all the internal links are relative URLs, they can then crawl and index the full site in whatever format. It will ultimately lead to a duplicate content issue.
Improve Internal Link Strategy
A <base href> tag on your site that was implemented wrong on the site alongside relative URLs creates another page that will land on a 404 error page.
For instance, on the category page of your e-commerce website, http://www.example.com/category/xyz.html, the base href tag reads:
<base href=”http://www.example.com/category/xyz.html”/> and relative URLs internal link (/category/abc.html).
As Google crawls the internal links, it results in a 404 error page. See below.
http://www.example.com/category/xyz.html/category/abc.html
You can override this situation with the help of absolute links.
Helps Better Crawling
Google robots spiders follow the internal links present in your pages to crawl your site deeper. Google crawlers crawl a limited number of URLs due to its actual cost (crawl budget). So, if you have a million pages on your website, it will make sense for the bot to leave your site during the crawl Google frequently counters issues.
Google bots prefer spending their time on well-optimized sites. Using absolute URL helps Google in streamlining the crawling process. It saves crawl time and also encourages the bot to return frequently and crawl other pages.
85. Missing Schema in Technical SEO Audit
It might seem very hard to comprehend the language used to describe a schema error when you first look at it. But, all you need is to get acquainted with a couple of terms to be apple to identifying and rectify the errors
The table below includes a glossary of terms and their meanings.
|
Expression |
Meaning |
| Schema | XSD deines Schema. The schema displays the structure of an XML document:
|
| Entity | A single entity groups together a set of fields sharing the same relationship. |
| Field | A field (data item) is an entity’s attribute. You can see it as the short field name in the coding manual. |
| Reason for null | It describes an explanation for a null value in the field. It needs the following description like a reason code,like 2: not sought, 3: refused or 9: not applicable. |
| Parent element | XML consists of elements. Here ‘parent elements’.refers to entities. |
| Child element | XML comprises elements. Fields are the ‘child elements’ because they belong to the entity or ‘parent element’. |
| Nested | Fields and entities that belong to each other are referred to as nested. |
Worked examples of Invalid values schema errors for the DLHE record
The following examples display error messages stating the value returned to be invalid. This means the value does not conform to the valid entries present in the respective field descriptions.
If a value is referenced as ” it means the value is missing leaving a field in the file. Here is what it will look like in the file:
<EMPBASIS></EMPBASIS> or <EMPBASIS> </EMPBASIS>
Each field in the file should contain a valid code as the XML structure doesn’t provide blank values. Therefore, if the value is missing, you have the necessary input appropriately. If the value is not identifiable, and the field is not needed for the record, just remove the field from the file.
How to Understand if a Field Can be Removed
Look at the minimum and maximum occurrences present in the field detail of the coding manual. It will give you an idea whether it is feasible to exclude a field from the record.
A code has been returned in this version of the error message. But, it is invalid as it does not conform to the schema.
Schema checks are meant to maintain the accurate data of a list of valid entries, from code returned for the field as present in the coding manual. If you get such an error message, make sure to review and modify the data submitted accordingly.
86. Checking Missing Article or Blog Schema
See the following code, which displays the list of links of recent posts on an experimental blog site. Unfortunately, this code fails Google’s Structured Data Testing Tool. Why? It misses required items like the author and publisher.
If you do not want to show such data for your recent posts or every blog post, what should you do? Remove the structured data? Put the required stuff hiding it using CSS? You have to experiment with the available options and analyze the results to get the exact answer. This is what a technical SEO Audit can help with.
<section> <header> <h4 class=”h4-padding”>Recent Posts</h4> </header> <ul> <li> <article itemprop=”blogPost” itemscope itemtype=”http://schema.org/BlogPosting”> <header itemprop=”name headline”> <h5><a href=”http://myblog.com/post/5/1/2016/a-very-interesting-thing”>A very interesting thing</a></h5> </header> </article> </li> <li> <article itemprop=”blogPost” itemscope itemtype=”http://schema.org/BlogPosting”> <header itemprop=”name headline”> <h5><a href=”http://myblog.com/post/30/7/2015/something-even-more-interesting”>Something event more interesting</a></h5> </header> </article> </li> <li> <article itemprop=”blogPost” itemscope itemtype=”http://schema.org/BlogPosting”> <header itemprop=”name headline”> <h5><a href=”http://myblog.com/something-very-dull”>Something very dull</a></h5> </header> </article> </li> </ul>
87. Missing Sitelinks Search Box Schema
The search box of the site links provides a fast way to users to search your site or app immediately on the search results page. The search box offers real-time suggestions as well as other features.
Google Search can automatically display the search box in the site link of your website as appears in the search result. You do not require doing anything more to make this happen.
Google Search powers the scoped search box. But, you can do one thing. Provide information by adding WebSite structured data to help Google better understand your site. You can also control certain aspects of the site link search box with WebSite structured data.
88. Missing Review Schema
A review snippet is a short review or rating excerpt sourced from a review website. Typically, it provides an average of the rating scores from several reviewers. If Google uncovers valid reviews or rating markup, you can show the rich snippet, including stars and the summary data from reviews. Additionally, a rating evaluation can be displayed on a numeric scale (such as 1 to 5). Review snippets generally appear in rich results or the Google Knowledge Panels. Here are content types and subtypes that sites can supply ratings for.
89. Missing Product Schema
Suppose the product’s brand and manufacturer options are not configured correctly in the WooCommerce SEO plugin settings. In that case, it can lead to the warning missing field brand schema property in Google Search Console. This is why you must configure the product’s brand and manufacturer in WooCommerce SEO.
90. Missing Book Schema
Book actions serve as an essential entry point in Google Search. People want to discover books and authors. So, Google Search helps users instantly buy or borrow the books they can find directly in the search results. For example, a user that searches for Alice in Wonderland will be displayed with results that allow them to buy or borrow the book. As a book shop online, you can offer a data feed to Google having the structured data schema. This specification gives ReadAction to let users buy a book and the BorrowAction to help them borrow a book.
This is our comprehensive step-by-step guide for technical SEO audit by seo company India. If you want to get an insight personally into how it will be done for your business website, feel free to talk to our experts. We can also conduct a SEO technical audit for your website in the minimum possible time and offer you the best recommendations to make fixes to bring you on top.



